
Anthropic's Leak & The Scaffolding Map of AI
Premium Analysis

On March 31, 2026, security researcher Chaofan Shou posted a single line to X: “Claude code source code has been leaked via a map file in their npm registry.” Within hours, 512,000 lines of TypeScript — the complete internal architecture of Anthropic’s flagship agentic CLI tool — had been mirrored across GitHub, analyzed by thousands of developers, and forked more than 41,000 times.
Anthropic confirmed it wasn’t a hack. A 59.8 MB source map file, a debugging artifact that maps minified production code back to its original source, had been accidentally bundled into version 2.1.88 of the @anthropic-ai/claude-code npm package. Someone forgot to add *.map to .npmignore. The result: anyone who knew where to look could download the entire unobfuscated codebase directly from Anthropic’s own Cloudflare R2 storage bucket.
The internet reacted to the surface story — the human error, the irony, the GitHub star count. That reaction misses the point entirely.
What leaked wasn’t just code. What leaked was a design philosophy. And that philosophy — read carefully — answers a question the market has been circling without resolution for eighteen months: where is the AI market actually going, who is building the right things, and what does the competitive map look like when you strip away the benchmark noise?
This piece starts where the leak starts: inside Anthropic’s architecture. Then it uses that architecture as a lens to map the broader industry — because what Anthropic built and why they built it that way reveal more about the state of AI market development than any quarterly earnings call or benchmark release this year.
What the Architecture Actually Shows
Memory as Bandwidth Engineering
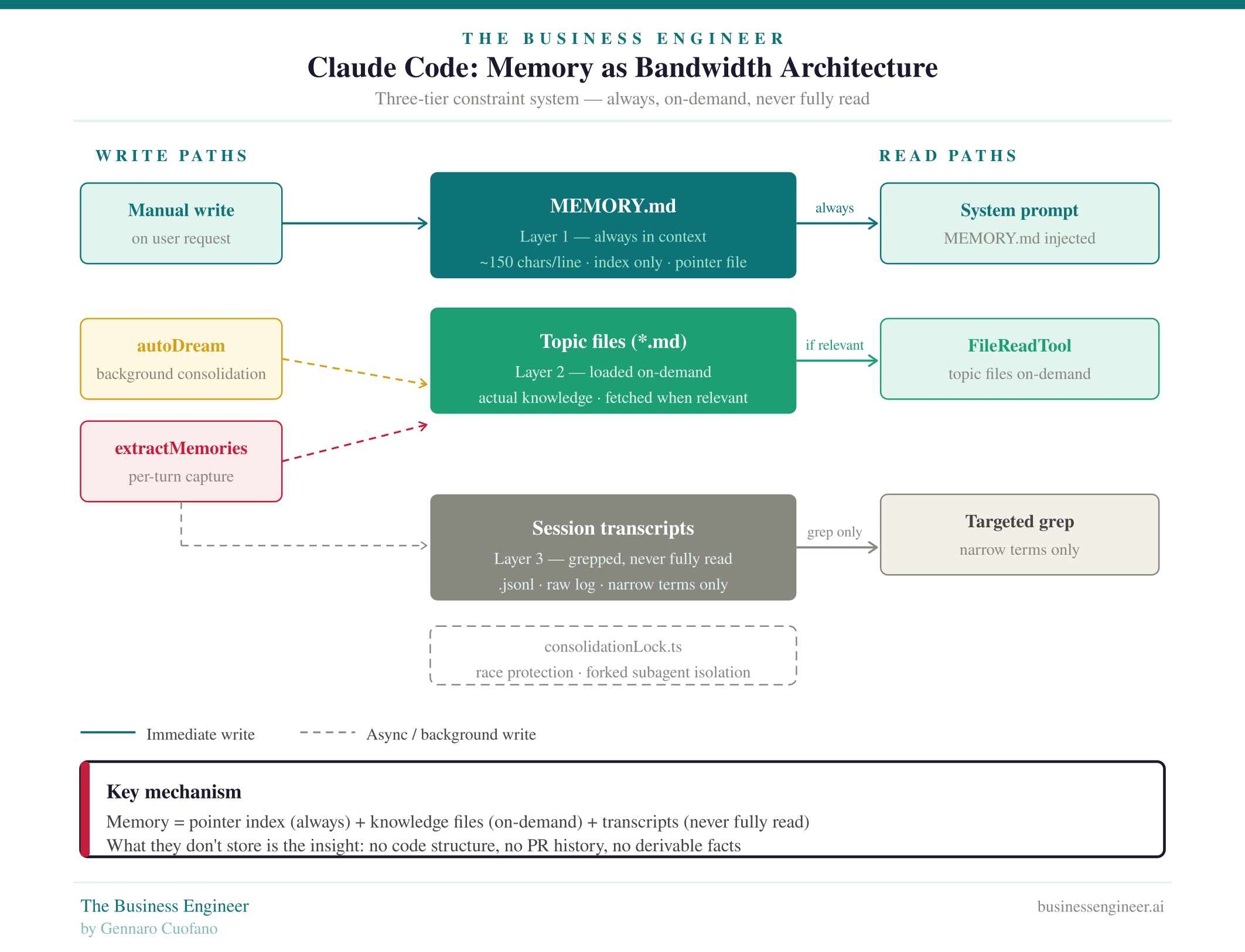
The most structurally important thing the leak revealed is not a feature. It is a design constraint — and the discipline with which Anthropic engineered around it.
The constraint: LLM context windows are expensive. Loading everything into context doesn’t scale. Any agentic system that tries to “remember everything” will either bankrupt its users on inference costs or collapse under the weight of irrelevant context polluting every response.
Anthropic’s solution: a three-tier memory hierarchy built entirely around bandwidth management.
Layer 1 — MEMORY.md (always loaded): A pointer index, not a knowledge store. Every entry capped at roughly 150 characters per line. Always injected into the system prompt. Contains only references to where real knowledge lives — never the knowledge itself. Think of it as a routing table, not a database.
Layer 2 — Topic files (on-demand): The actual knowledge, organized by subject. Fetched via
FileReadToolonly when the current session is relevant to that topic. Never preloaded. Never in context unless needed.Layer 3 — Session transcripts (never fully read): Raw
.jsonllogs of every interaction. These are never loaded into context. They are only ever grep’d with narrow search terms to surface specific signals. The logs exist. The context cost of reading them does not.
The write discipline is equally important:
Write to topic file first, then update the index — never the reverse.
Never dump content into the index. The index is a pointer, not a store.
Code-derived facts are never stored. If something can be reconstructed from the codebase at runtime, it is never persisted.
No debugging logs, no PR history, no code structure. If it’s derivable, don’t persist it.
This last principle — the derivability rule — is the real insight. It forces a discipline that most data systems never impose: persistent state should only contain what cannot be reconstructed on demand. Applied consistently, it keeps the index clean, the context cost low, and the signal-to-noise ratio high across sessions of any length.
What this architecture is doing, structurally, is solving a physics problem. Context windows are a scarce resource. The architecture is designed to extract maximum utility from that resource by never spending it on anything that doesn’t need to be there. This is constraint-driven engineering applied to cognition — and it is considerably more sophisticated than anything visible in competitor tools from the outside.

