
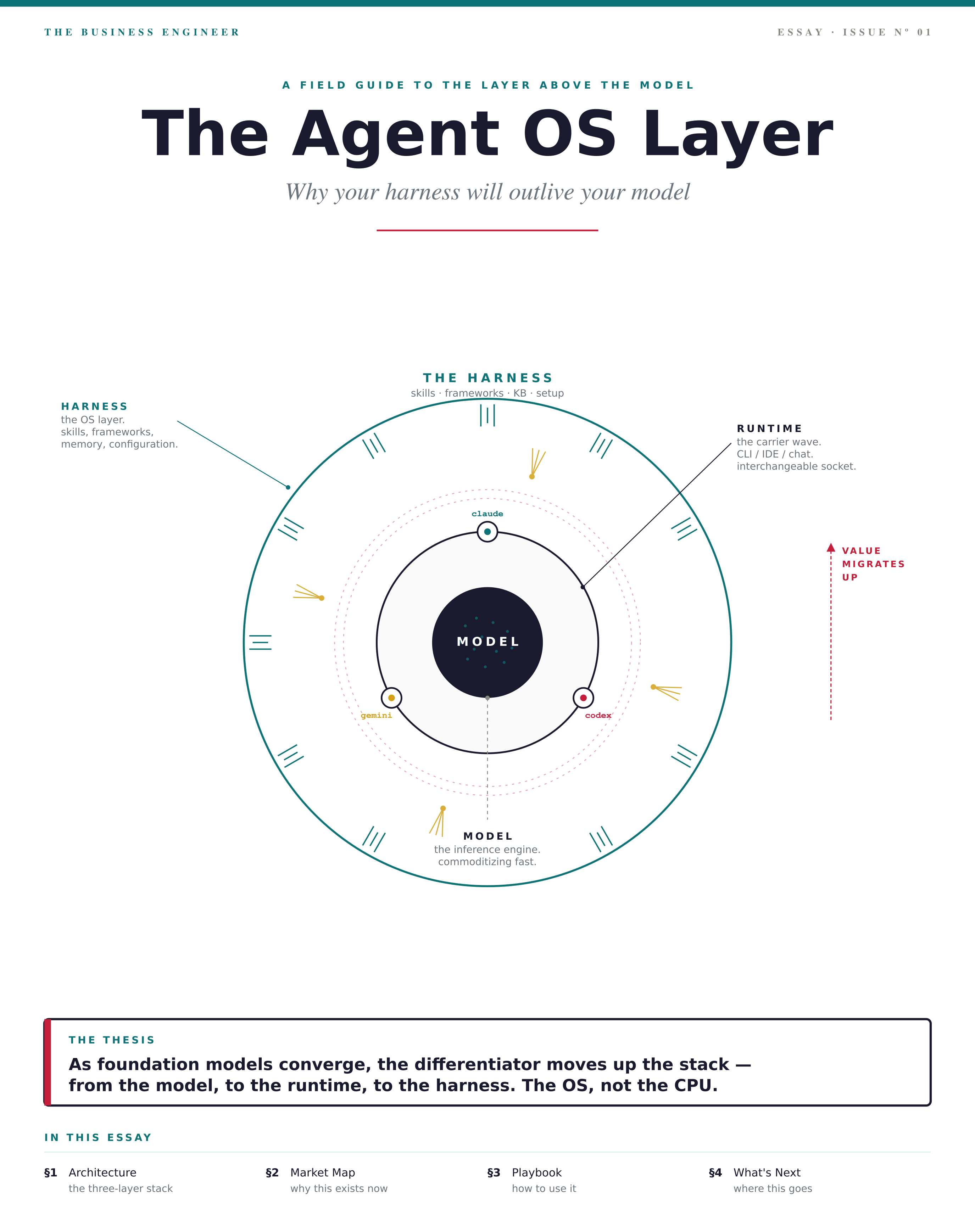
The Agent OS Layer

Open ChatGPT. Vague prompt. Wall of text. Copy-paste somewhere, lose the context, start over tomorrow. That’s the chatbot loop — an inference engine with no operating system around it. The Agent OS Harness breaks the loop by sitting between you and the model, turning the same inference into a structured executive analyst that remembers what it learned. The model is the engine. The harness is the OS.
Skills are the apps: structured markdown files telling the agent what to do, how to format output, how deep to reason. Each skill is portable, reusable, and version-controllable.
Frameworks are the kernel: mechanism-first reasoning, evidence standards, compression protocols. Invariants enforced at every step, not optional.
The KB is the filesystem: every analysis distilled and written back. Memory compounds. The agent gets sharper because past work is input to future work.
Setup is the boot sequence: seven questions on role, industry, priorities — then the harness configures itself. No YAML. No config files. Just answer.
The runtime is the socket: Claude Code, Gemini CLI, OpenAI Codex. Same skill library. CLAUDE.md / GEMINI.md / AGENTS.md are interchangeable carriers.
The compression: as foundation models converge, the differentiator moves up the stack — from the model, to the runtime, to the harness. The OS, not the CPU.

Architecture — the three-layer stack

Most people see two layers in their AI workflow: the model (Claude, GPT, Gemini) and the interface (chat window, CLI). They’re missing the third, and it’s where the leverage lives.
Layer 1 — Model. The inference engine. Commoditizing fast. Capabilities are converging across providers within months, not years.
Layer 2 — Runtime. The CLI or app that connects you to the model. Claude Code, Gemini CLI, OpenAI Codex. These exposed the model in a way that the chat window never did — they gave you a session you could configure, files the agent could read on startup, slash commands you could define.
Layer 3 — Harness. What gets loaded into the runtime. Skills, frameworks, knowledge base, configuration. This is the operating system layer — the part that decides what the agent knows how to do, how it thinks, and what it remembers.
Without a harness, every session starts at zero. The model is brilliant; the agent is amnesiac. With a harness, every session compounds. Same model. Different machine.
Market Map — why this category exists now
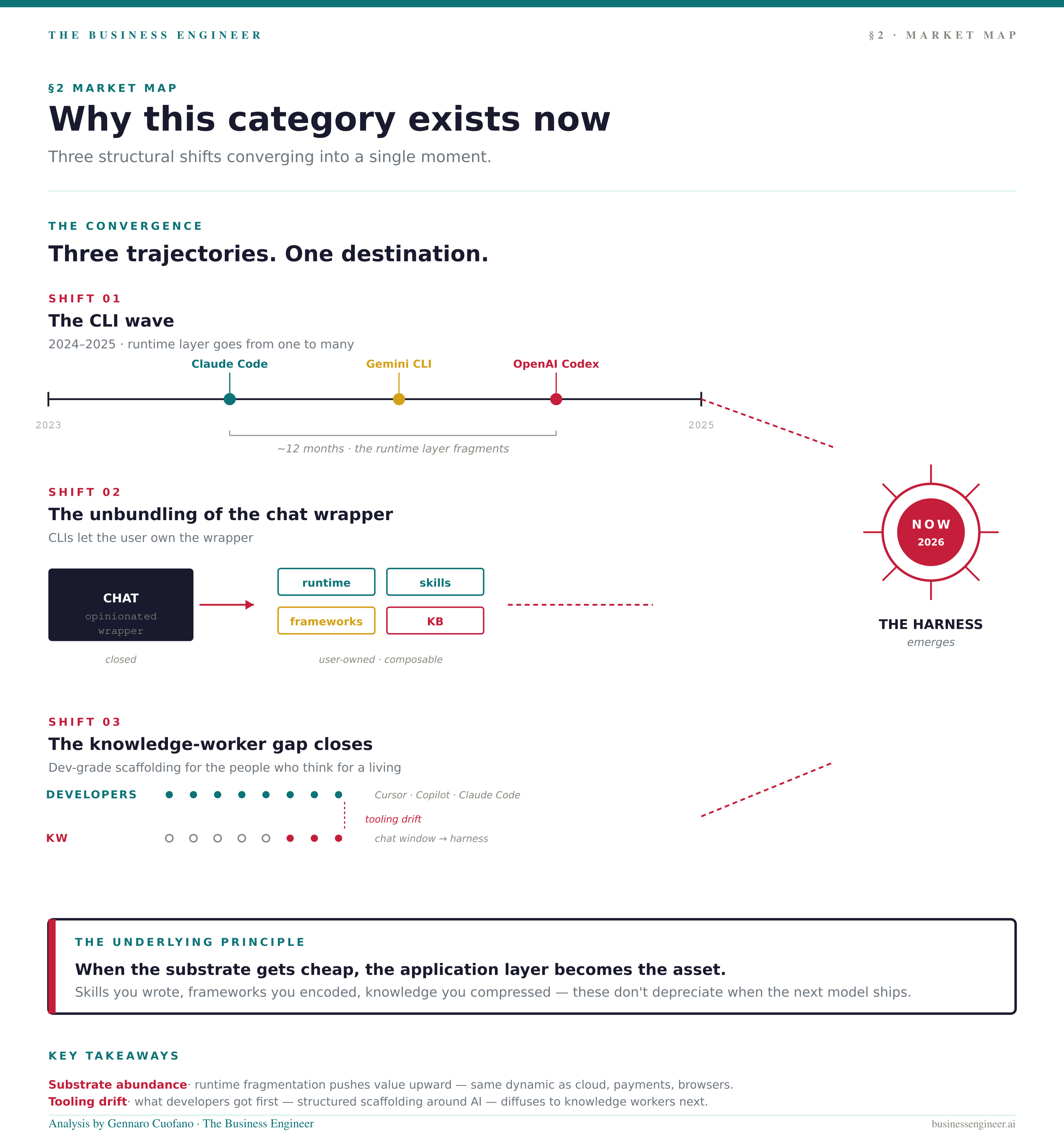
The Agent OS Harness wasn’t possible 18 months ago. Three structural shifts made it inevitable:
The CLI wave (2024–2025). Claude Code, Gemini CLI, and OpenAI Codex shipped within roughly twelve months of each other. The runtime layer went from one (chat) to many (CLI + chat + IDE plugins). Once runtimes are abundant, value migrates up the stack.
The unbundling of ChatGPT. The chat interface was an opinionated wrapper. You couldn’t open it up. CLIs broke that open — they let the user own the wrapper. The harness is what fills the wrapper.
The knowledge-worker gap. Developers got Cursor, Copilot, Claude Code. They got real productivity scaffolding around AI. Knowledge workers — VPs, founders, consultants, analysts — got a chat window and a “you’re using AI wrong” article. The Agent OS Harness is the developer-grade tooling brought to the people who think for a living.
Underneath all three: when the substrate gets cheap, the application layer becomes the asset. Skills you wrote, frameworks you encoded, knowledge you compressed — those don’t depreciate when the next model ships. They get more valuable.
Playbook — what changes when the agent has an OS
The contrast is sharper than it looks:
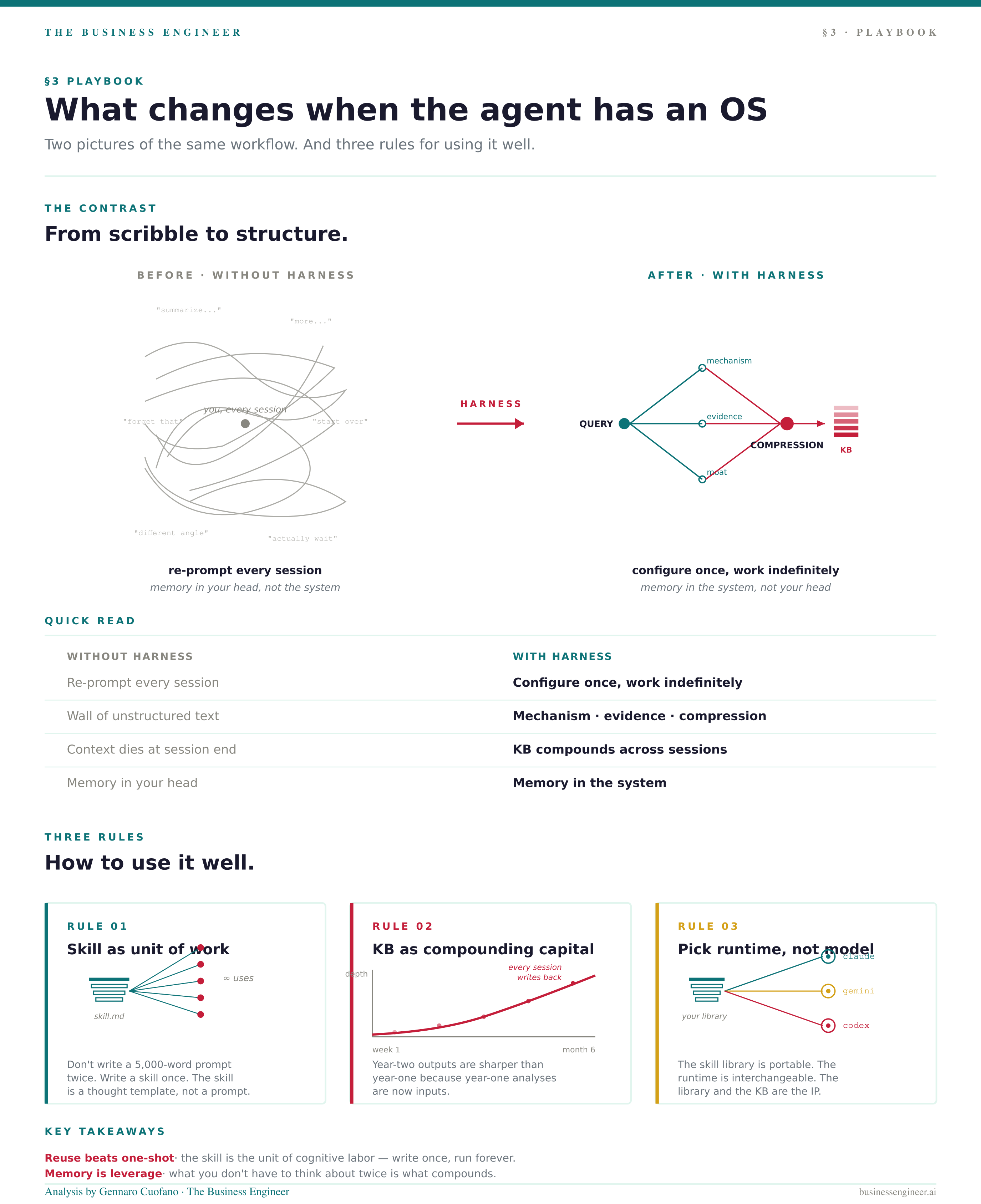
Three rules for using it well:
Treat skills as the unit of work. Don’t write a 5,000-word prompt for the same task twice. Write a skill once. Skills are cheaper than prompts because they’re reusable, structured, and improvable. The skill is a thought template before it’s an instruction.
Treat the KB as compounding capital. Every analysis writes back. Year-two outputs are sharper than year-one outputs because year-one analyses are now inputs. The compounding curve is invisible at week one and dominant at month six.
Pick the runtime, not the model. The skill library is portable. CLAUDE.md today, GEMINI.md tomorrow, AGENTS.md for Codex. The runtime is interchangeable. The skills and the KB are yours. That’s the IP.
What’s Next — where this goes

Three things to watch over the next 18 months:
Skill marketplaces. When skills are portable, structured, and standalone, they become tradeable. Expect a Hugging Face equivalent for skill libraries — competitive analysis skills, board-prep skills, M&A workup skills — sold or shared across the people who use them. The skill becomes the unit of cognitive labor, not the prompt.
Team-shared knowledge bases. Personal KBs are stage one. Stage two is shared institutional memory — five analysts contributing compressions into one team KB, querying each other’s prior work. The flywheel that took McKinsey three decades to build becomes accessible to a four-person strategy team in a quarter.
Runtime routing. Different models will be cheaper, faster, or smarter for different jobs. The harness becomes a router: this skill runs on Claude, that one on Gemini, this background task on a small local model. The user keeps one interface. The harness handles the routing.
The endgame: the model becomes a utility. The runtime becomes a substrate. The harness becomes the product.
With massive ♥️ Gennaro Cuofano, The Business Engineer