The Agentic Expansion Cascade

The agentic expansion theory — sandbox → tool use → computer use → convergence — is usually read as a product roadmap. Each lab ships the next phase; each phase looks like a feature release.
The structural reading is different. The expansion is not a product decision. It is the substrate requirement of the scaling law that now defines AI progress. Once that is seen, the cascade across the rest of the AI map is not a forecast — it is a settlement.
This piece has two parts. Part I explains why the expansion is happening, from the AI scaling perspective. Part II runs the cascade forward across the seven layers of the AI map that result in a reprice.
PART I — Why This Is Happening
The Scaling Laws Stack. They Do Not Sequence.
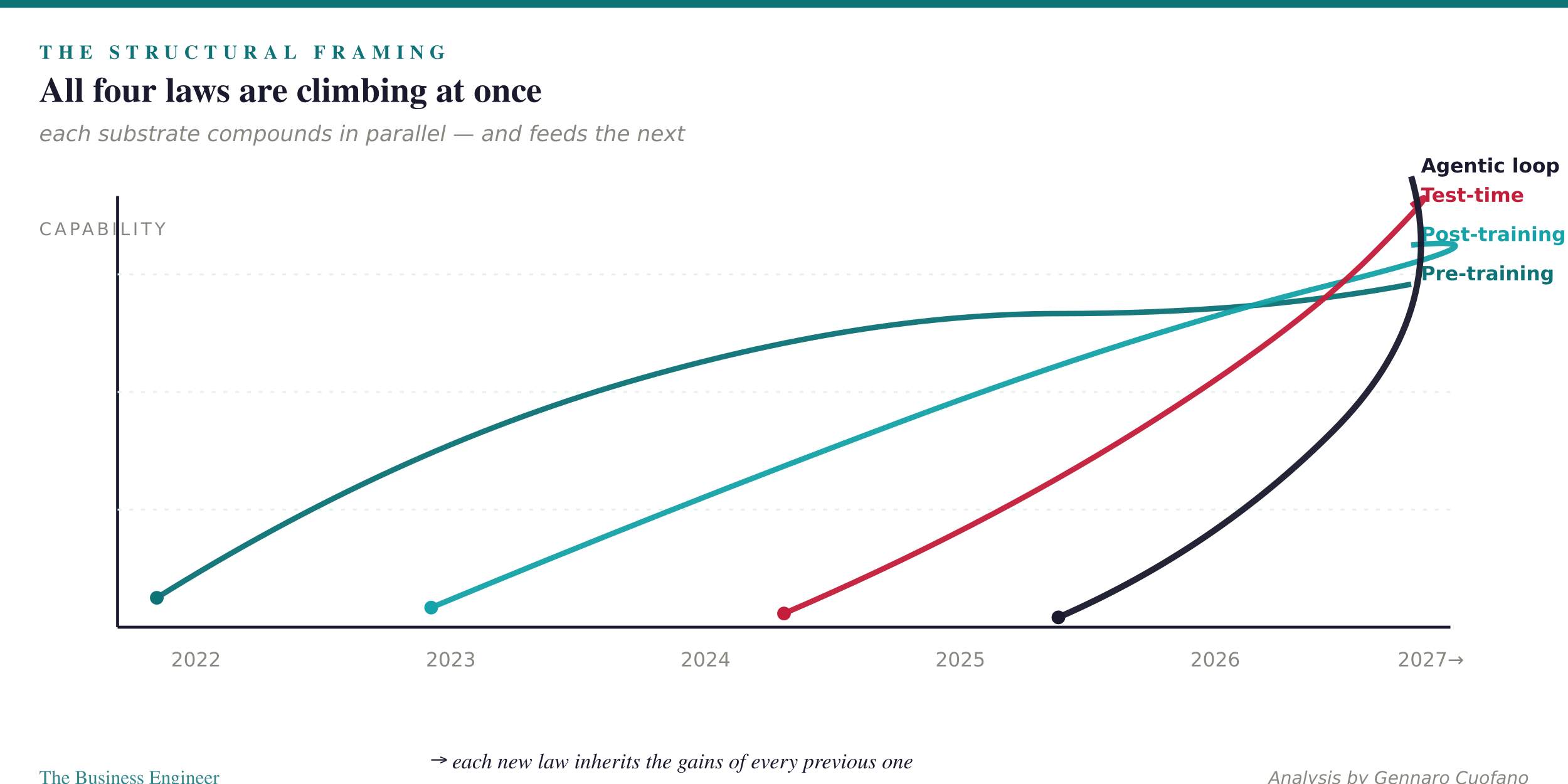
The standard narrative treats AI scaling as a sequence. Pre-training was 2022–2023. Post-training was 2023–2024. Test-time compute was 2024–2025. Agentic loops are 2025–2026. Each paradigm “replaced” the last. That framing is wrong in a way that matters for capital allocation and product strategy.
None of these paradigms got replaced. Pre-training is still compounding — Opus 4.6 and 4.7 sit on trillions of parameters. Post-training is still compounding — RLHF, RLAIF, outcome-based fine-tuning are improving every release. Test-time compute is still compounding — reasoning modes burn more inference per query each generation. What changed is that we moved from one scaling law at a time to four scaling laws running in parallel, each feeding the next.
The new frontier is not which law wins. It is how tightly each law feeds the next. Whoever owns the loop between the layers owns the rate of capability gain.
Each Law Requires Its Own Substrate
The reason scaling laws stack rather than sequence is that each one feeds on a different kind of fuel — a different substrate to press against:
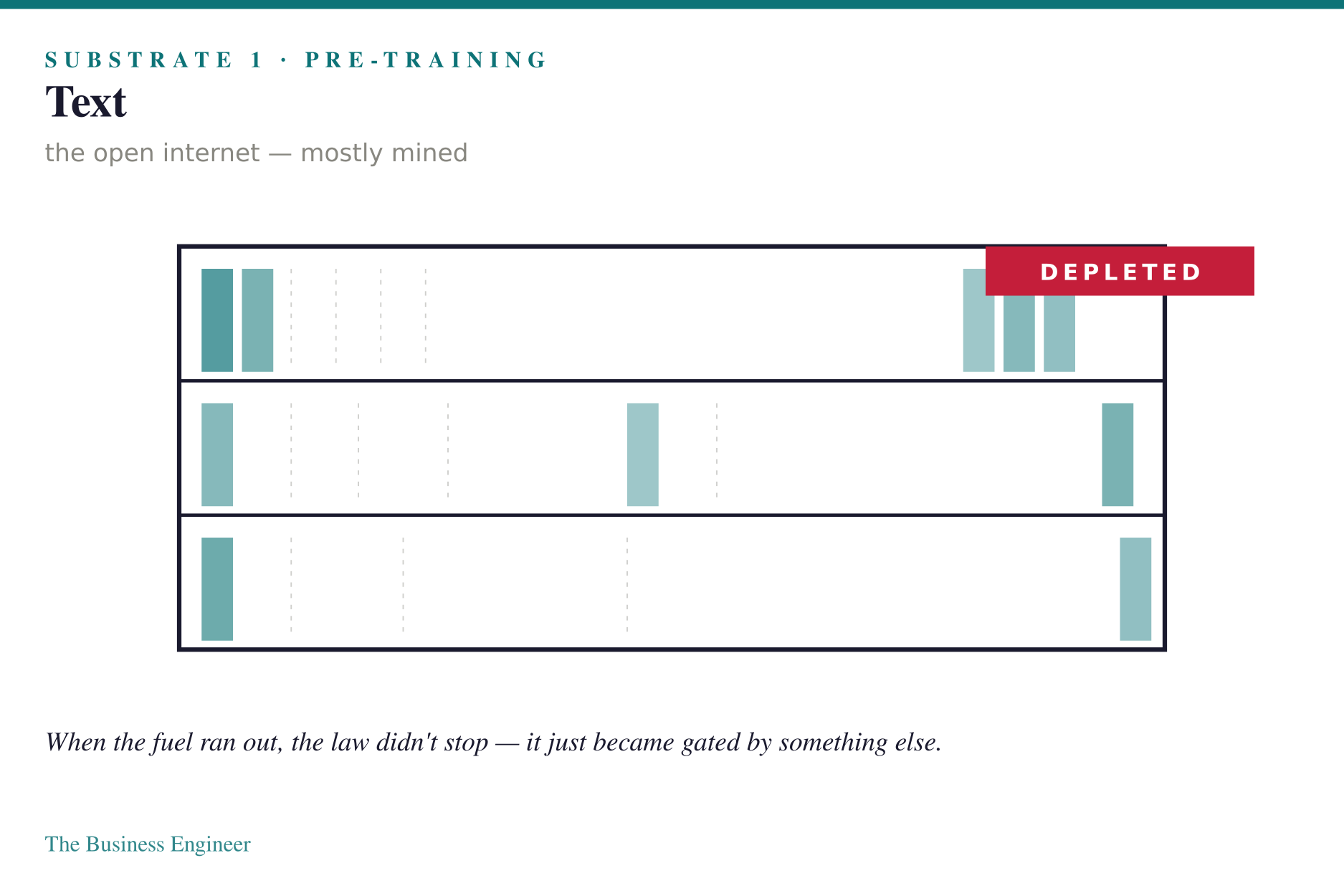
Pre-training fed on text. The open internet — a vast corpus of human-produced language that taught the model to compress the world into next-token predictions. When that fuel began to run out, the law did not stop compounding. It just became gated by something else.
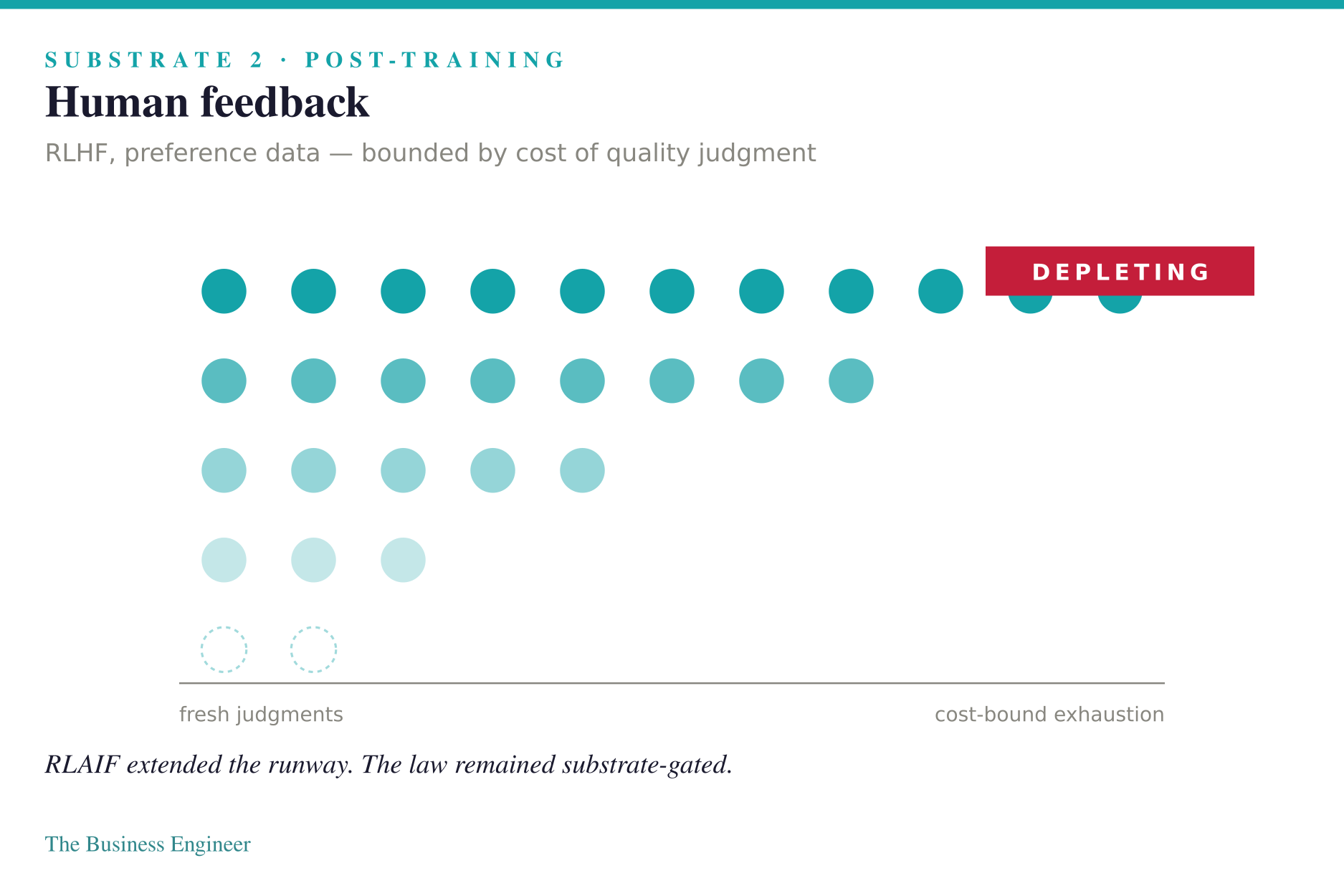
Post-training fed on human feedback. RLHF, preference data, expert demonstrations — the second substrate was the alignment of model behavior to human judgment. Finite in a different way: bounded by the cost of generating quality feedback. RLAIF extended the runway, but the law remained substrate-gated.
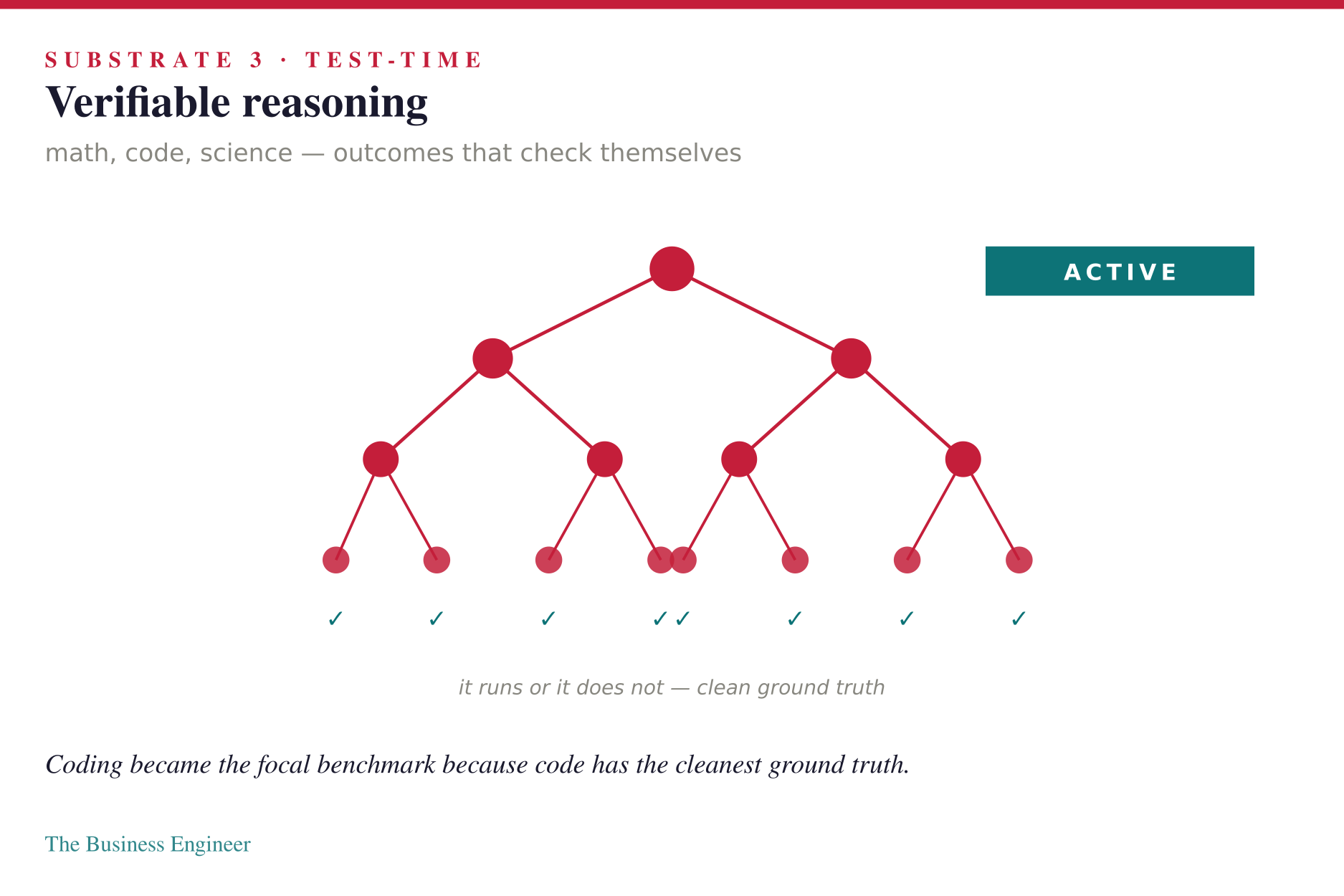
Test-time scaling fed on verifiable reasoning. Chain-of-thought, problem decomposition, deep reasoning at inference. Math, code, science. The reason coding became the focal benchmark of the era is that code has the cleanest ground truth: it runs or it does not.
The fourth scaling law — the agentic loop — feeds on environments. Not text, not feedback, not reasoning problems. Environments. Actual computers, actual tools, actual outcomes the agent observes, retries, learns from. The fourth law cannot scale on benchmarks alone. It can only scale where the agent can act, fail, and observe consequences.

The Sandbox Is the Product
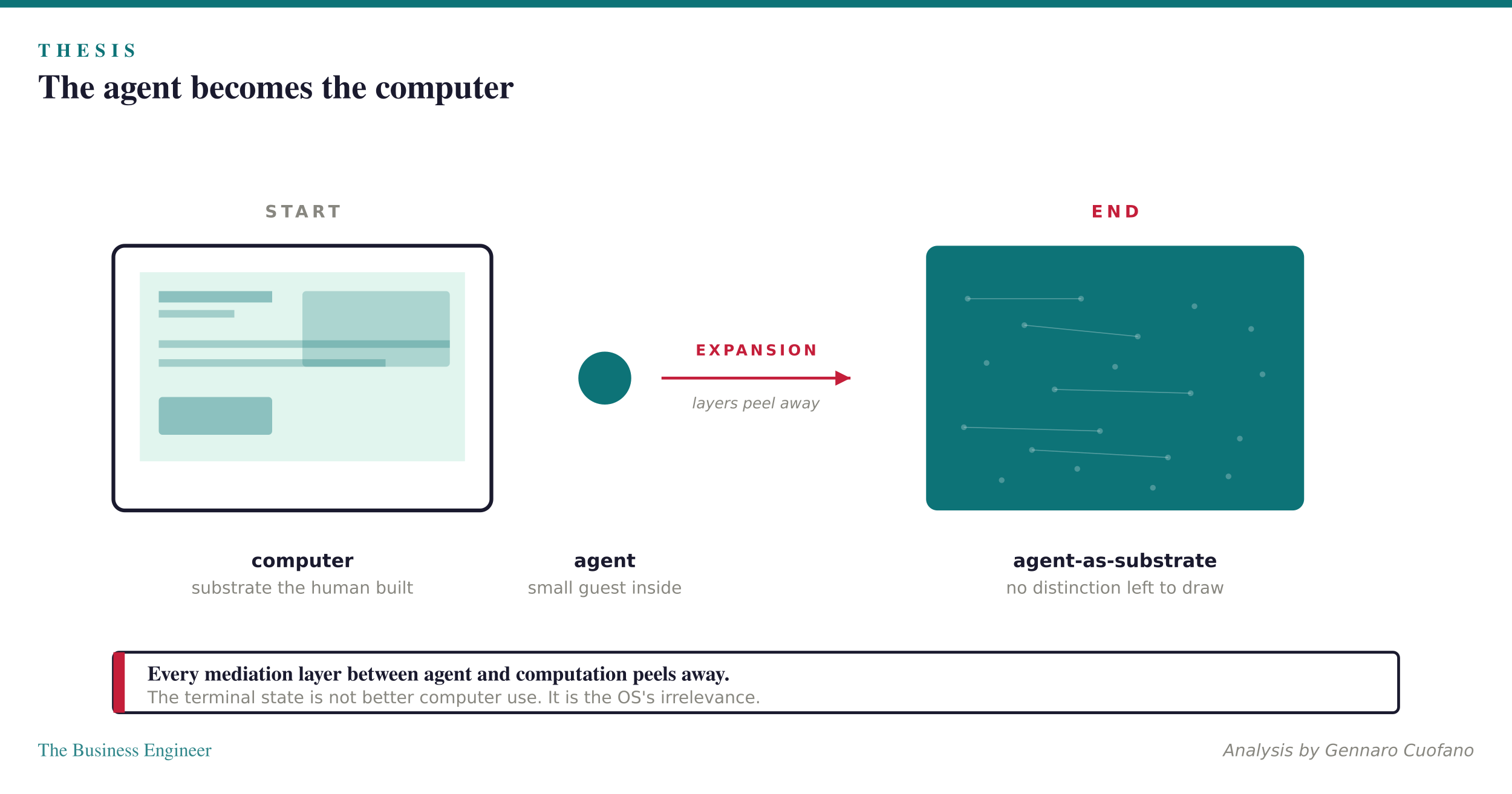
This is the architectural insight that ties the expansion to the scaling law. The sandbox the agent operates in is no longer a containment strategy. It is the training substrate.
The traditional reading of computer use is risk management — the lab “lets the agent out” of the cage just enough to do useful work, with guardrails to prevent misuse. That reading misses the structural point. The sandbox is not the cage. It is the environment in which the next generation of agents is being trained. Every Claude Computer Use session, every Perplexity Computer execution, every Operator browser run is a data point that feeds back into the next scaling-law iteration.

The cleanest formulation of this insight came out of analyzing Claude Cowork’s architecture: the sandbox is the new product. Not the output of the sandbox — the output is whatever the agent produced. The sandbox itself. Its design determines what the agent can learn, how fast it converges, and what next-generation capability it unlocks. The agent does not need freedom; it needs a wall to press against. Compute is not a cost — it is the substrate of convergence.
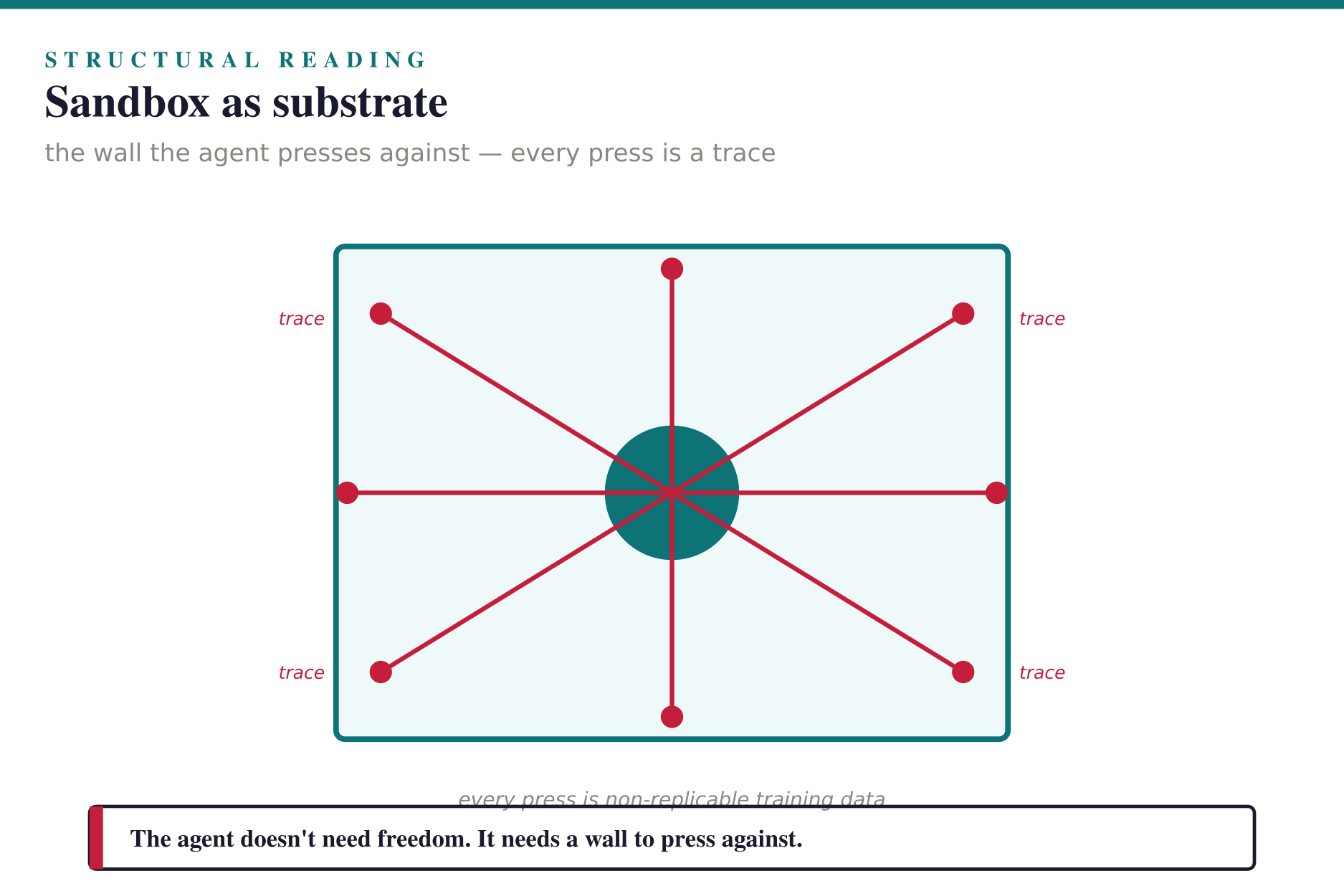
The wider the sandbox, the larger the surface area against which the fourth law can press. Sandbox expansion is therefore the binding constraint on the fourth scaling law.
Therefore Computer Use Is Not a Feature
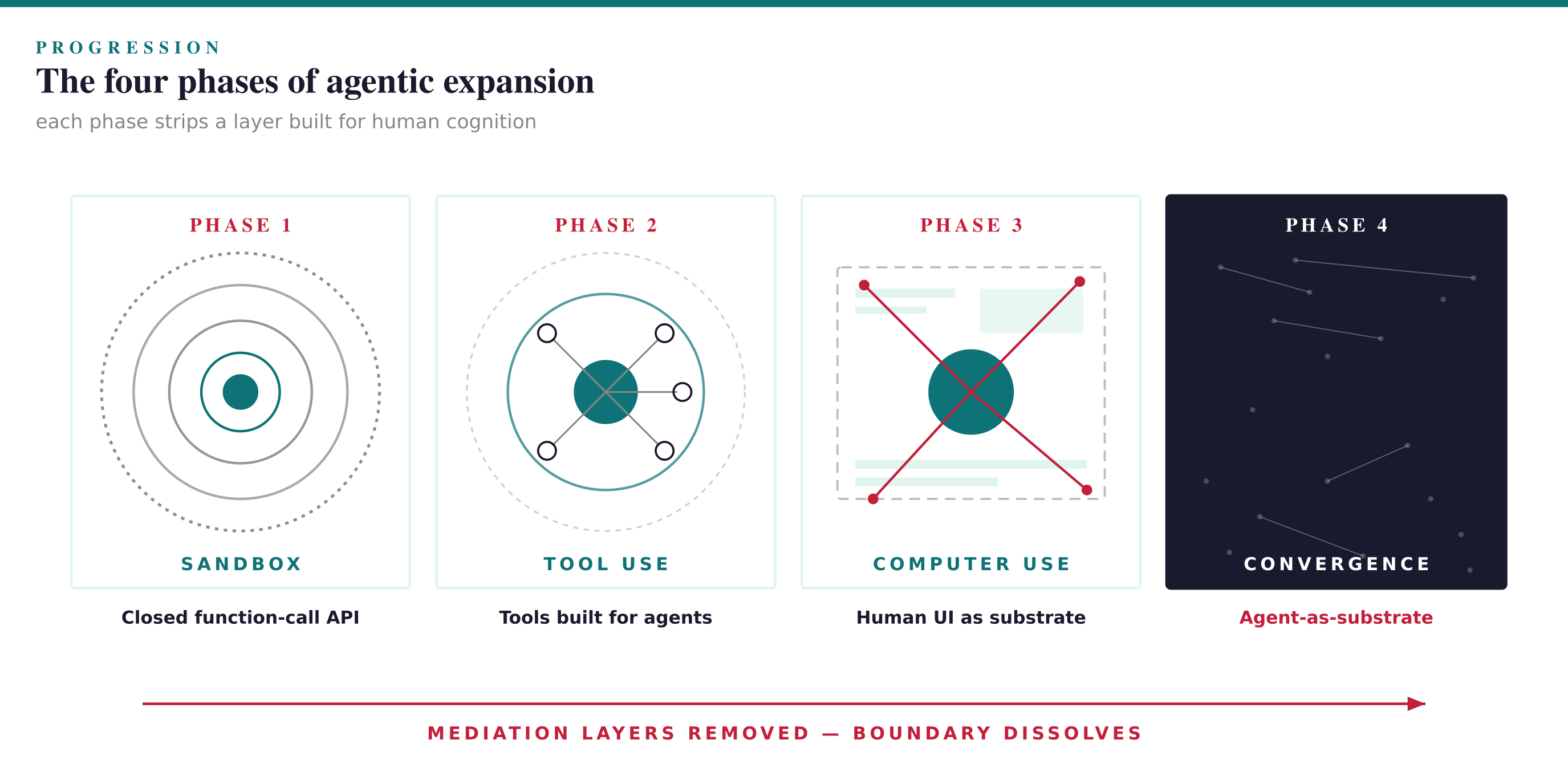
Once the substrate logic is seen, the agentic expansion theory becomes inevitable rather than strategic:
Phase 1 (closed sandbox) was the substrate that pre-training fed on, externalized as a product surface.
Phase 2 (tool use) was the substrate that post-training and test-time scaling fed on.
Phase 3 (computer use) is the substrate the fourth scaling law requires.
Phase 4 (convergence) is the asymptote of the fourth scaling law — the limit where the agent’s training environment is indistinguishable from the world the agent operates in.
Every frontier lab is racing to ship Phase 3 and 4 not because the product market demands it but because the next capability jump depends on it. Without an expanded sandbox, the fourth law has nothing to climb on. Anthropic shipping Claude Computer Use on March 23. Perplexity declaring Personal Computer. OpenAI building agent-first hardware with Qualcomm. These are not competing product roadmaps. They are the same scaling-law substrate, instantiated differently.
This is the deep reason the agent absorbs the computer. The sandbox keeps widening because the scaling law requires it to. At the asymptote, the sandbox is the world and the agent is the computer.

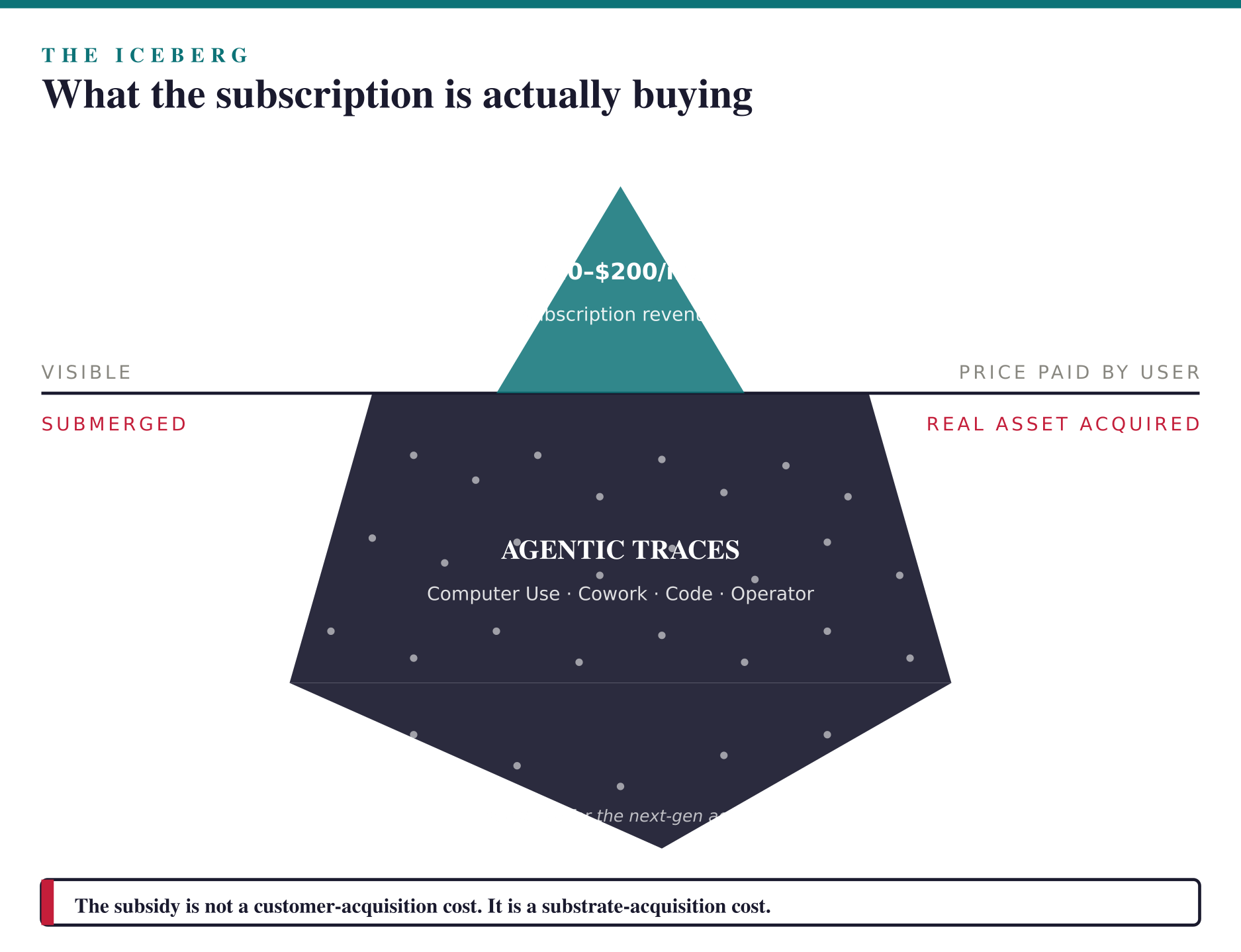
The Subsidy Economy Is the Cost of Substrate Acquisition