
The AI Value Chain

Today, the AI value chain is built on a complex ecosystem that spans hardware, cloud, software, AI models, and vertical and consumer applications.
This is an ecosystem in full development, where rather than demand bottlenecks, there are supply bottlenecks.
This means the ecosystem is still developing to cover for a potential embedding of AI into every possible commercial use case.
Yet, this process might take a couple of decades to develop fully to accommodate the mass adoption of AI and to make inference available to everyone.

In the last few weeks, I’ve been tackling a key topic in tech: competition from multiple perspectives.
There, I’ve started by defining what it means to build AI moats if you’re outside the frontier model stack.


At the same time, I’ve covered how what I’ve called competitive moating got to be seen from how you translate a tech moat into a “market power” that lasts.
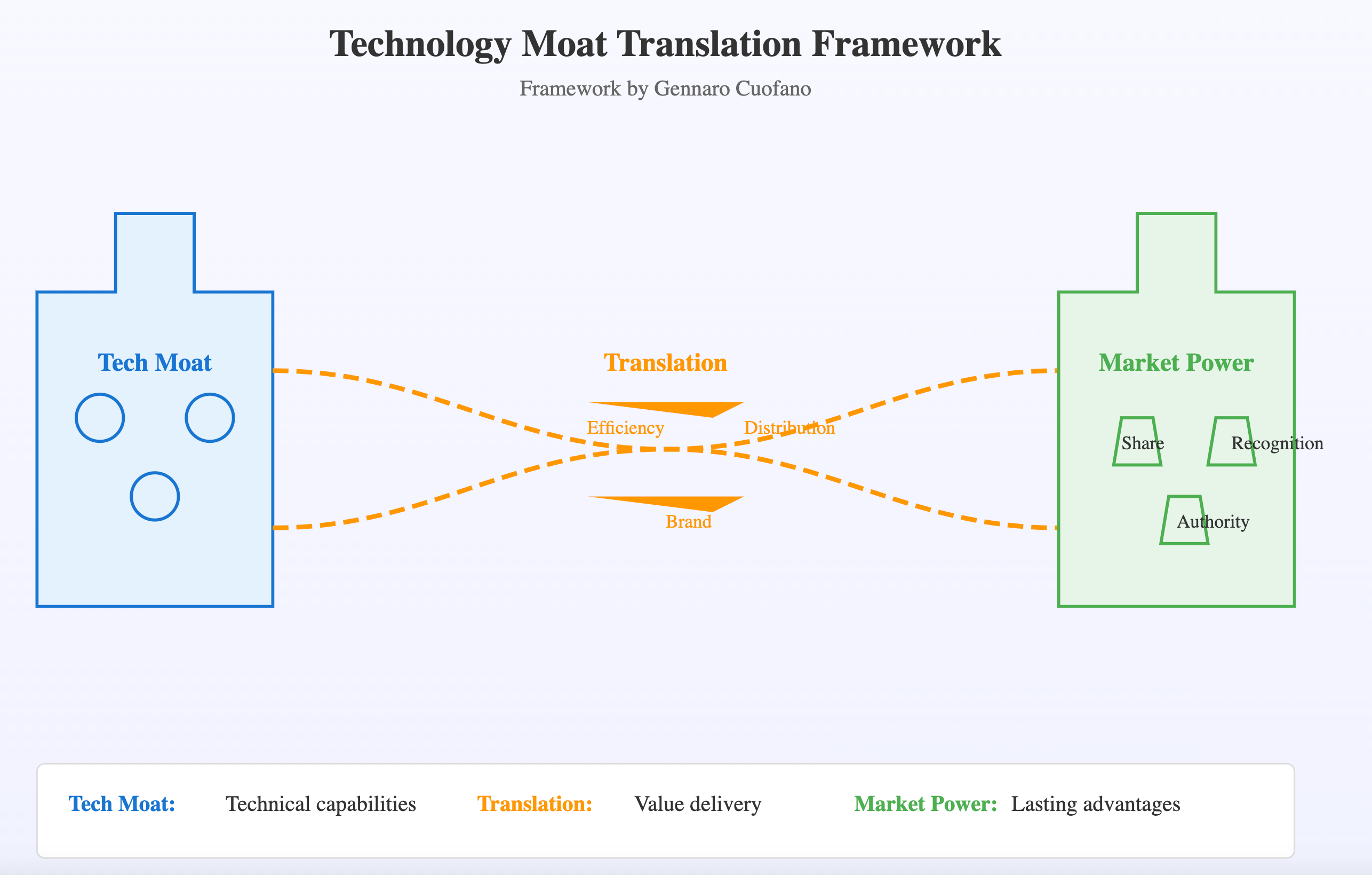

So that you can build a business model scaling advantage.
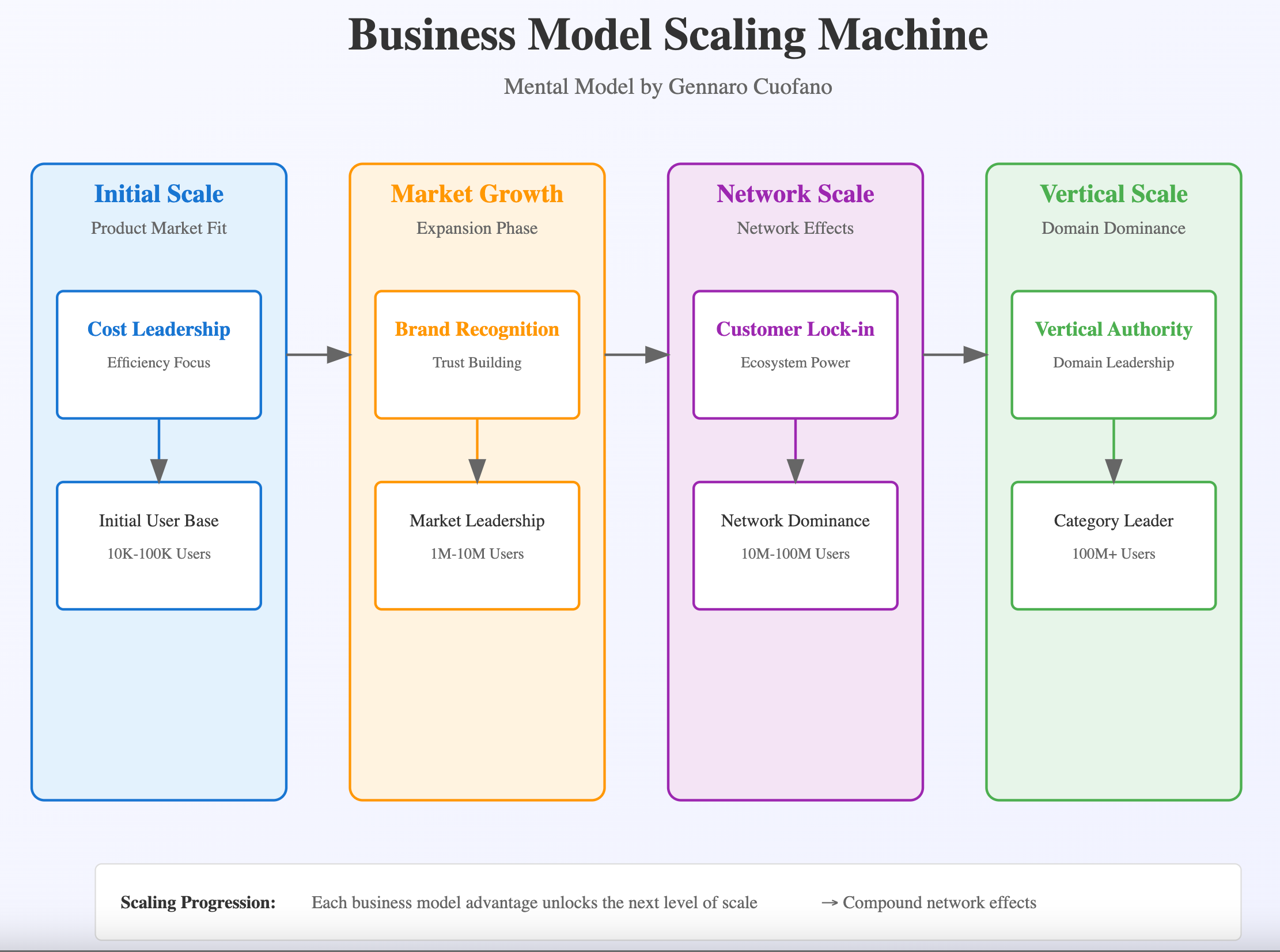
The bad news is that if your company has started before the current AI paradigm, you have quite some work to do to adapt to the new playbook.
However, for “AI-native companies,” the playbook above is ingrained in how they operate to their core.

Before we look at the world of competition in AI, let’s first look at the ecosystem to give you a complete mapping of it.
The AI Ecosystem: A Primer

The AI ecosystem is evolving around a layered structure that starts with hardware at the base, powering advanced models and specialized computation.
On top of that, cloud services provide scalable training and inference capacity, enabling robust AI model development.
Vertical AI applications deliver targeted solutions for specific industries, while consumer apps bring AI directly to end users in everyday contexts.
Finally, AI‐specific consumer hardware integrates the entire stack into tangible devices.
This layered approach shapes each company’s competitive advantage based on where in the stack they operate, the value they deliver at that layer, or the intersection of each layer.
That’s how you map out competition in the AI industry!
That also means that for some players, it will make sense to do business only within a narrow section of the layer, while for others, it will make sense to expand across a good chunk of the stack.
No player, for now, will ever be able to cover the entire layer, which would make no sense from a competition standpoint, as it would require a gigantic level of vertical integration that might also become a burden rather than a competitive edge.
However, if you are Google, OpenAI, Microsoft, Amazon, or Meta, you want to have your moat built around a few layers of the stack or at the intersection of a few pockets of various layers.
This is part of an Enterprise AI series to tackle many of the day-to-day challenges you might face as a professional, executive, founder, or investor in the current AI landscape.

Fabs and Foundries
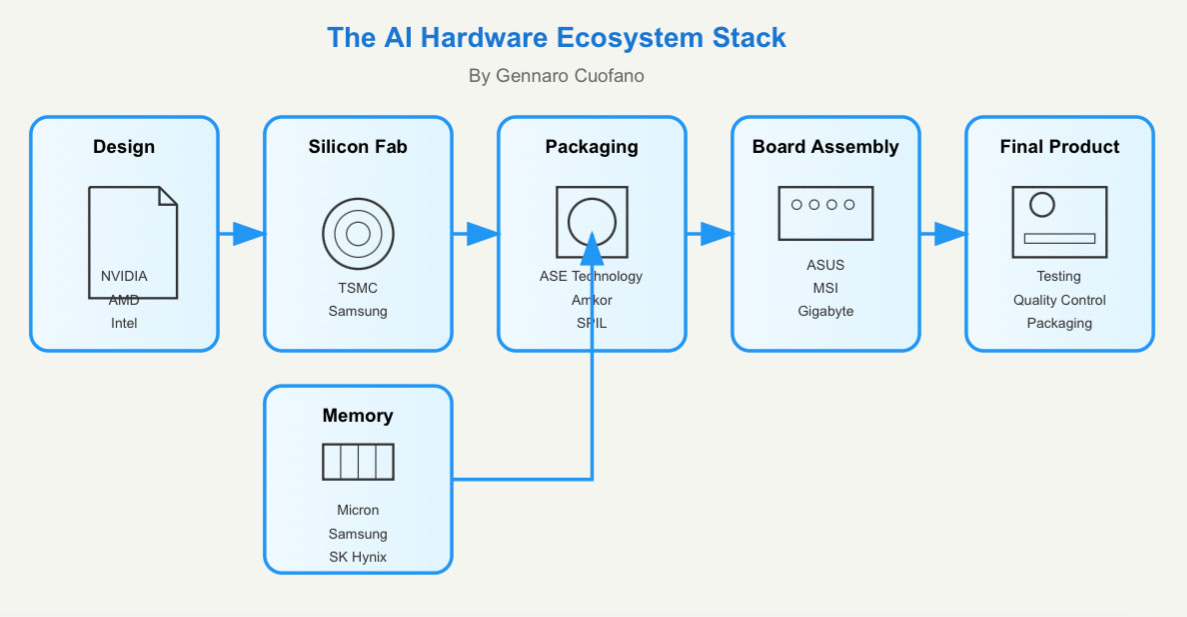
For the sake of this discussion, I’m leaving out the fabs and foundries part of the stack.
Why? Well, we’ll get to the point where Fabs and Foundries also become a piece of the stack where massive investments will go to build new ones, but it’ll be a process we’ll see in the next 20 years.
Indeed, I argue that this AI ecosystem is developing with a sort of alignment between public and private, which, at a certain stage, will also lead to massive infrastructure investments that will flow into the energy and fabs stack.
We’re not there yet and’ll get there in the coming decade.
But for now, let’s look at the AI hardware layer and what makes it up.

Core Hardware Layer

This layer is comprised of a few critical building blocks:
AI Chips:
GPUs (Graphics Processing Units): Widely used for AI due to their parallel processing power.
TPUs (Tensor Processing Units): Custom hardware optimized for deep learning.
Neural Processing Units (NPUs): Specialized chips designed to accelerate AI workloads.
AI Accelerators: General term for hardware boosting AI computations.
Memory Systems:
High Bandwidth Memory (HBM): A high-speed memory architecture that supports AI workloads.
On-chip Cache Systems: Reduces memory bottlenecks for faster AI processing.
Memory Fabric Architecture: Optimized memory interconnect for efficient data access.
Specialized Processors:
Matrix Multiplication Units: Critical for AI tasks like deep learning.
Vector Processing Units: Enhances performance for AI computations.
Custom ASIC Designs: Application-specific integrated circuits for AI models.
Interconnect:
High-speed Data Bus: Enables efficient data movement.
Network-on-Chip (NoC): Improves communication within AI chips.
Scalable Fabric Design: Ensures adaptability for AI workloads.
How do all these pieces come together?
A key thing to understand here is that these various pieces come together as an “integrated ecosystem,” as most of these pieces work in unison, especially on the training side, to enable high performance.
While on the inference side, performance still matters, a data factory can be a little less efficient and still get the most out of it.
For that, you need to understand how the various pieces come together:
Processing Units: GPUs, TPUs, NPUs, and other AI accelerators serve as computational engines, each optimized for specific types of AI workloads. These units perform the heavy lifting of AI computations, such as matrix multiplications and vector operations, which are fundamental to tasks like deep learning.
Interconnect:
High-speed Data Bus: This component facilitates rapid data transfer between the processing units and other components, such as memory systems. It ensures that data is quickly moved to where it is needed, minimizing bottlenecks and latency.
Network-on-Chip (NoC): This interconnect fabric manages communication within the AI chip. It provides a scalable and efficient way to route data between different processing units, memory systems, and other components. The NoC ensures that data flows smoothly, even as the complexity and scale of AI workloads increase.
Scalable Fabric Design: This design principle ensures that the interconnect infrastructure can adapt to different workloads and system configurations. It allows for flexible scaling, enabling the AI chip to handle varying computational demands efficiently.
Integration:
The processing units are connected via the high-speed data bus and NoC, allowing them to communicate and share data efficiently. This integration ensures that computational tasks can be distributed across multiple processing units, leveraging the strengths of each type of processor.
The scalable fabric design of the interconnect infrastructure supports the dynamic nature of AI workloads, allowing the system to allocate resources as needed. This adaptability is crucial for handling the diverse and often unpredictable computational requirements of AI applications.
Data Flow:
Data flows from memory systems (like HBM and on-chip caches) to the processing units via the interconnect infrastructure. The NoC and high-speed data bus ensure that data is routed efficiently, minimizing delays and maximizing throughput.
The processing units perform computations on the data and send the results back through the interconnect infrastructure to be stored in memory or used in further computations. This seamless data flow is essential for achieving high performance in AI tasks.
Let’s dive deep into the actual hardware ecosystem.
AI Hardware Ecosystem

