
The Claude Code OS
Available In The Exec Membership

The next professional jump is not a better prompt. It is an operating system that wraps your AI — a harness that compresses your thinking, your team’s feedback, and the model’s raw capability into something replicable. Without it, AI works for you. With it, AI works for your team.

Architecture
The stack beneath the stack
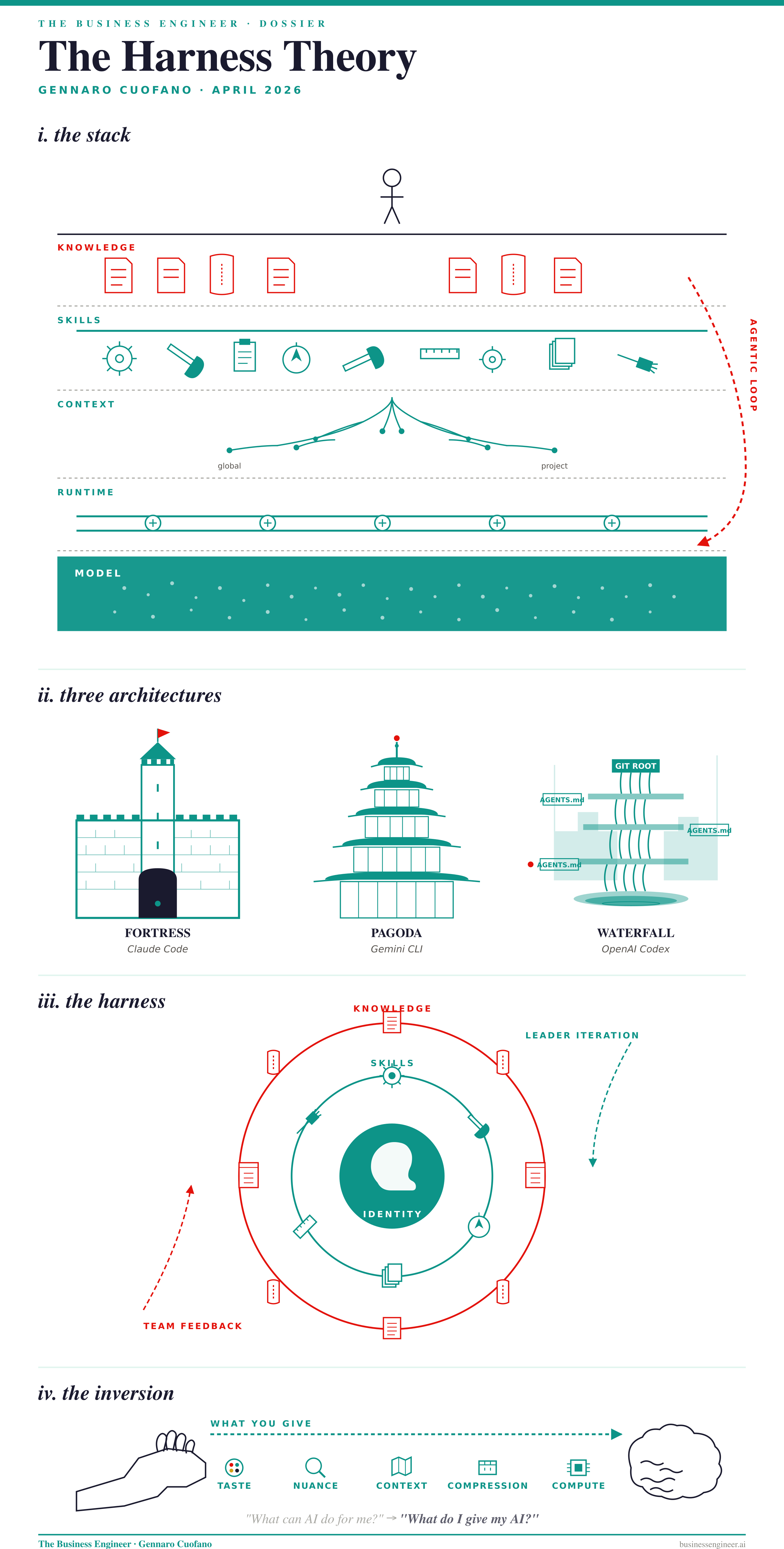
Most people see AI as a chat box. That framing is already obsolete. What is actually running, when an agent does something useful, is a layered architecture — and the layer that matters most is not the model.
The model is the floor. Above it sits the runtime, which gives the agent its hands: tool use, file access, skill execution. Above that is the context — global plus project — which tells the agent where it is. Above that are skills, the compressed reusable instructions that let the agent operate outside its training distribution. And at the top sits knowledge — the artifacts the agent produces and that your team consumes.
The structural point hiding inside this stack is the one most observers miss. It is fashionable to say “scaling is dead.” That is not what the data shows. Pre-training scaling has become incremental. Post-training scaling is incremental. Agentic-loop scaling has barely begun. Frontier labs are now training their next models on what their agents did — compressing tool-use behavior back down into the weights. The runtime, the context, the skills are not separate from the model. They are the next training set. The model layer of the stack is in motion, and the layers above it are what put it in motion.
This is also why the harness is not optional. Without one, you face the reset problem: AI is not deterministic, so the same prompt today and tomorrow will not produce the same output. Replicability — the precondition for any team-level system — has to be built outside the model, in the harness.
Market Map

Three harnesses, three postures
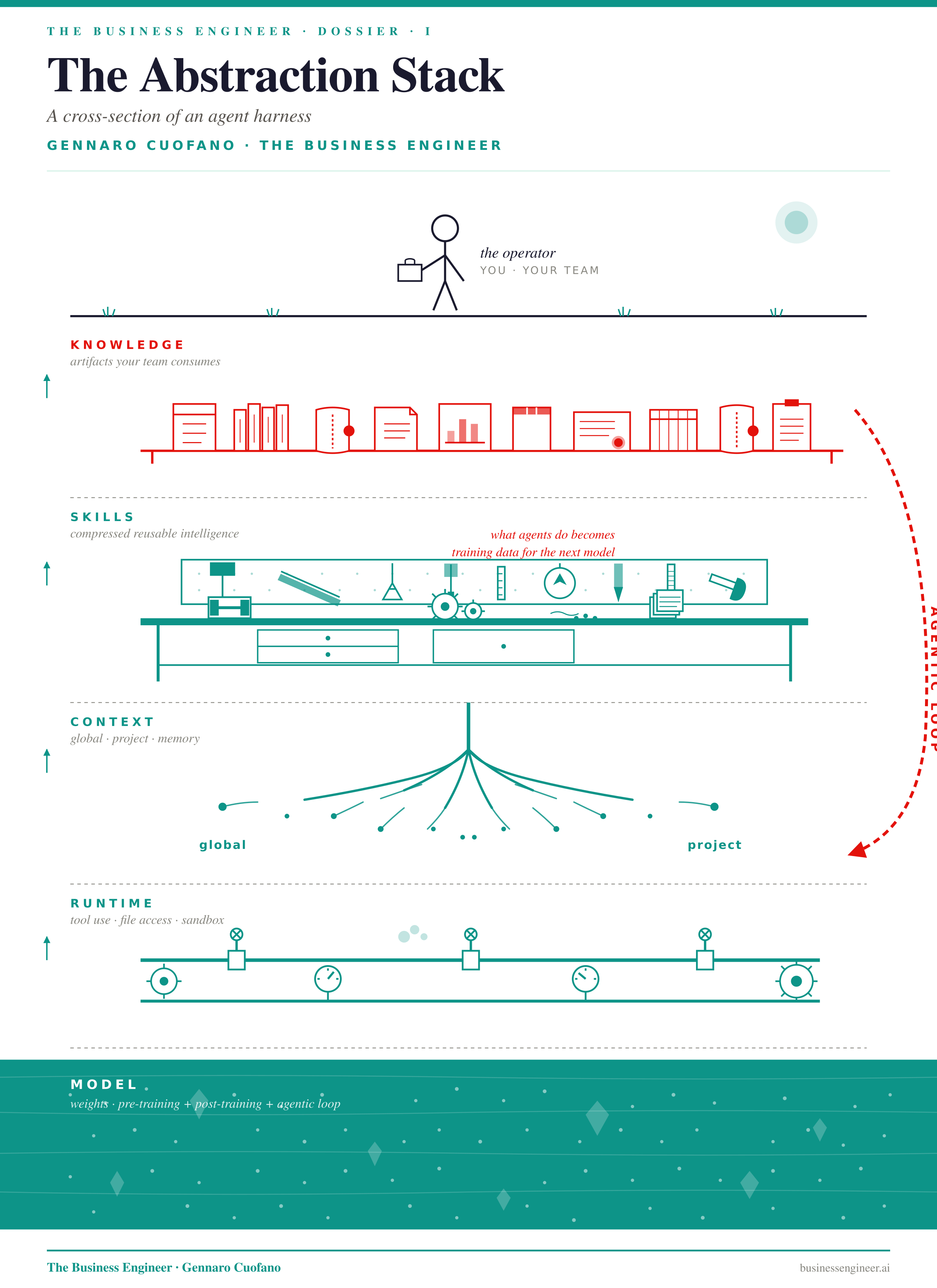
The terminal — the command-line interface — turned out to be where agents actually live. Not because programmers love it, but because a CLI is the cleanest sandbox: bounded enough to be safe, open enough to control a whole machine. Every serious agent harness in 2026 is, at its core, a CLI architecture.
Three matter. They are not interchangeable. They are different operating philosophies, and the right move is not to pick one — it is to run all three and learn where each is strongest.
Claude Code is a fortress. Flat, self-contained, two inputs (global + project). The agent gets a briefing and operates with autonomy. Tool use is deep, the context window is large, the skill model is composable. It is the right harness when the task is well-bounded and you want maximum agency inside the box.
Gemini CLI is a pagoda. Layered tiers — global workspace at the base, project in the middle, component on top — with context inheriting upward. Less self-driving than the fortress today, but the structure is more transparent, and as Google invests deeper into the agentic side, this architecture will compound.
Codex is a waterfall. It starts at the git root and cascades downward, directory by directory, with each AGENTS.md able to override its parent. This is why coders working at scale love it: it can inspect and operate on enormous codebases in a way the fortress cannot. Its auto-trigger is sharper than Claude Code’s; its self-contained autonomy is shallower.
The point is not to choose. It is to run all three and let each cover the weakness of the other two.
This is the multi-architecture posture. As a business engineer — generalist by design, supporting many teams across many tasks — being locked into a single vendor’s CLI is a structural mistake. Each harness is a different way of compressing context, skills, and execution. The professional who can move between them, knowing which one to deploy for which problem, builds the only durable edge: independence from any single platform’s roadmap.
Playbook
Identity, skills, knowledge
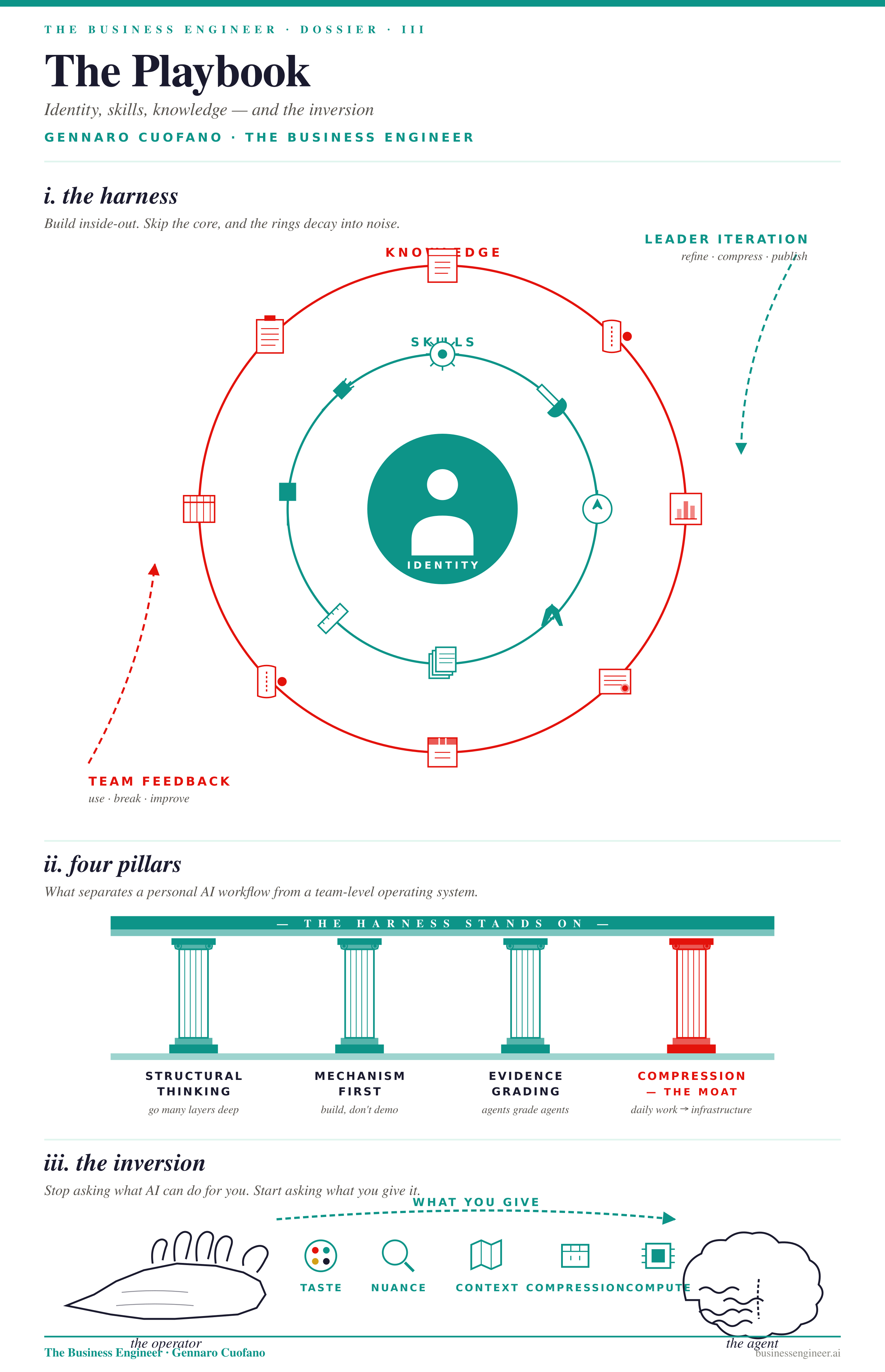
Inside any harness, regardless of which CLI you run it on, the architecture decomposes into three concentric layers. They have to be built in order. Skip the inner one, and the outer ones decay into noise.
Identity is the core. Before anything else, the agent has to know who it is operating for. Role, profession, voice, what counts as good output in your real world. Without identity, every skill becomes generic and every output reverts to the model’s default register. This is why a serious harness walks you through an identification process the first time you run it — it is building memory before it builds capability. A product manager helping their team execute ideas faster does not need the same harness as a financial analyst writing structured memos. Both share the same model. Both diverge entirely once identity is set.
Skills are the middle ring. A skill is compressed intelligence — a reusable unit that turns a one-time prompt into a repeatable protocol. Skills have layers: metadata, inputs, the procedure itself, the output format, and quality gates that the model uses to check its own work. Skills should not be generic; if a skill could just as easily be replaced by prompting, it adds no value. As models get more capable and learn to use tools and MCPs natively, the value of generic skills decays toward zero. Skills earn their place by guiding the agent outside its closed environment — into the long tail of your specific real world, the place where power-law dynamics live and where the model’s defaults stop being useful.
And skills are not static. They evolve in two directions. Leader iteration: you compress new patterns into them as you learn. Team feedback: the people who use the skills push back, break them, force them to improve. A harness without both feedback loops is a frozen artifact, not a living system.
Knowledge is the outer ring. The artifacts the harness produces — analyses, decks, reports, code, drafts — that your team consumes and acts on. This is where the harness pays for itself. If the only person benefiting from your AI workflow is you, the harness is doing 10% of its job.
The inversion
The fundamental error in how most professionals approach AI is a question framing problem. They ask: “What can my AI do for me?” The harness theory inverts that question.
An agent harness in 2026 needs five things from you, and they are mostly things AI cannot get on its own: taste (what good looks like in your domain), nuance (the edge cases the model has never seen), context (where this output will land and who will read it), compression (skills that turn one-time work into reusable systems), and compute (the actual machine cycles to run the loops). Strip any of those, and the harness underperforms. Provide all of them, and the same model produces work that looks an order of magnitude better — because the model is the same; everything around it is different.
When the harness underperforms, the failure mode is almost always input-side, not capability-side. The agent is more capable than the work it produces. What it lacks is what only you can give it.
The four pillars
This is also why the four pillars of a serious harness are non-negotiable. Structural thinking — never operate on the surface; go many layers deep until you reach a mechanism, not a narrative. Mechanism-first — build systems your team can actually use, not demos. Evidence grading — sub-agents that evaluate the work of other agents and force self-improvement, because a harness that cannot grade itself cannot compound. Compression — every daily task becomes a reusable unit, every reusable unit becomes infrastructure for the next one.
These are not nice-to-haves. They are what separates a personal AI workflow from a team-level operating system. They are what makes a harness composable: each piece works alone, and the pieces work together as a stack.
What’s Next
Compounding curves and the team-level moat
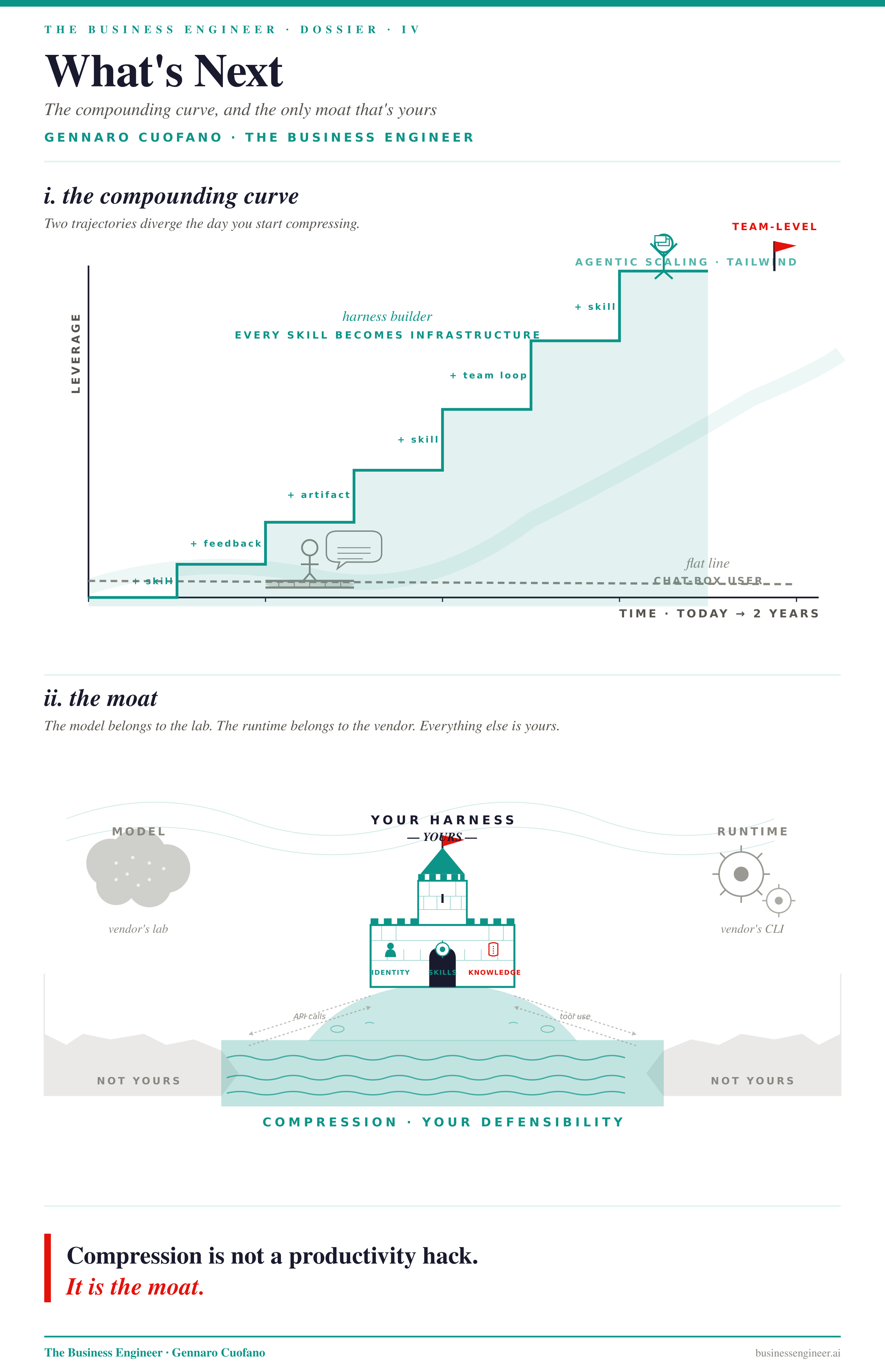
The next two years of frontier AI will be defined by the agentic scaling law. Frontier labs are now in a feedback loop where their next pre-trained model is partly trained on what the previous generation’s agents did — every successful tool use, every multi-step task, every recovered failure becomes training signal compressed back into weights.
This is why the model layer of the abstraction stack is going to keep moving, and why the harness layer above it is going to keep mattering. As models compress more agentic intelligence into fewer parameters, the gap between an operator with a harness and an operator without one widens, not narrows.
For a business engineer — or anyone whose value depends on systems thinking applied across teams — the implication is sharp. The professional who builds a harness today is not just running AI better.
They are building a compounding curve: every skill compressed becomes infrastructure for the next skill, every team feedback loop becomes signal for the next iteration, every artifact produced becomes a reusable substrate.
The professional still using AI as a chat box is on a flat line. They are getting better outputs, perhaps, but the outputs do not stack into a system, and the system is where leverage lives.
The harness is the only place this compounding can live. The model belongs to the lab. The runtime belongs to the CLI vendor. The context, the skills, the knowledge — those are yours, and they are where your defensibility sits. This is the shift from individual contributor to system architect, and it is the only version of the AI story that has team-level economics behind it.
Compression is not a productivity hack. It is the moat.
Key Takeaways & Mental Models

Harness Theory — a non-deterministic model becomes replicable only when wrapped in identity, skills, and knowledge layers operated through a CLI sandbox.
The Abstraction Stack — model → runtime → context → skills → knowledge; each layer compresses the one below it, and the agentic loop now scales by feeding the top layers back into the bottom.
Multi-Architecture Posture — running Claude Code (fortress), Gemini CLI (pagoda), and Codex (waterfall) in parallel removes single-vendor lock-in and lets each architecture cover the others’ gaps.
The Inversion — an agent’s underperformance is almost always input-side — taste, nuance, context, compression, compute — not capability-side; the question to ask is what you give the AI, not what it gives you.
Compression Loop — a harness compounds because skills evolve in two directions: leader iteration tightens them, team feedback breaks and rebuilds them — turning daily work into team-level infrastructure.
Recap: In This Session!
The next professional jump is not a better prompt
It is a harness: an operating system around AI that makes work repeatable, team-usable, and compounding
Without a harness: AI helps the individual
With a harness: AI becomes team infrastructure
The Architecture: The Stack Beneath the Stack
Most people see a chat box. The real architecture is layered:
Model
The capability floorRuntime
Tool use, file access, skill executionContext
Global and project-specific memorySkills
Reusable compressed proceduresKnowledge
Artifacts the team consumes and acts on
Key idea:
The model is not the whole system. The layers around it determine whether AI becomes reusable infrastructure.
Why the Harness Matters
AI is non-deterministic. The same prompt does not reliably produce the same output.
So replicability must be built outside the model through:
identity
context
skills
quality gates
feedback loops
Conclusion:
The harness is what turns AI from a chat interface into an operating system.
Three Harness Architectures
Claude Code: Fortress
Flat and self-contained
Strong autonomy inside a bounded box
Best for well-scoped tasks where deep agency matters
Gemini CLI: Pagoda
Layered context hierarchy
More transparent structure
Likely to compound as Google deepens agentic investment
Codex: Waterfall
Cascades through codebase directories
Strong for large repositories
Excellent for codebase-scale inspection and execution
Strategic point:
Do not pick one. Run all three. Each compresses context and execution differently.
Multi-Architecture Posture
A serious operator should avoid CLI lock-in.
Why:
each harness has different strengths
vendor roadmaps are unstable
cross-harness fluency becomes strategic independence
Edge:
Knowing which harness to use for which task becomes a professional advantage.
The Three Concentric Layers
1. Identity
The agent must know who it serves.
Includes:
role
voice
standards
domain taste
what “good” means
Without identity: outputs revert to generic model defaults.
2. Skills
Skills are reusable protocols.
A strong skill includes:
metadata
inputs
procedure
output format
quality gates
Rule:
A skill must encode domain-specific judgment. If it can be replaced by a prompt, it is not a real skill.
3. Knowledge
The output layer:
analyses
reports
decks
code
briefs
reusable artifacts
Payoff:
The harness creates work your team can consume, reuse, and improve.
The Inversion
The wrong question:
“What can AI do for me?”
The better question:
“What do I need to give AI so it can perform at a high level repeatedly?”
The five inputs:
taste
nuance
context
compression
compute
Failure mode:
When AI underperforms, the issue is usually input-side, not capability-side.
The Four Pillars of a Serious Harness
Structural Thinking
Go beneath surface narratives to mechanisms.
Mechanism-First Execution
Build systems the team can actually use.
Evidence Grading
Use agents to evaluate other agents and improve output quality.
Compression
Turn repeated tasks into reusable infrastructure.
The Compounding Loop
A harness improves through two feedback channels:
Leader Iteration
You compress new patterns into better skills.
Team Feedback
Users break, stress-test, and refine the system.
Result:
Daily work becomes reusable infrastructure.
What’s Next
Agentic Scaling Law
Frontier labs are learning from agent behavior:
tool use
multi-step execution
recovery from failure
workflow traces
These behaviors become future training signal.
Implication:
The model layer keeps improving, but harness quality becomes even more valuable.
Strategic Implications
Individual Level
A harness turns personal AI use into a repeatable system.
Team Level
A harness becomes shared operating infrastructure.
Business Level
The defensibility sits in:
context
skills
knowledge
feedback loops
Not in the model.
Mental Models
Harness Theory: AI becomes replicable only when wrapped in identity, skills, and knowledge
Abstraction Stack: model, runtime, context, skills, knowledge
Multi-Architecture Posture: use multiple harnesses to avoid platform lock-in
The Inversion: AI quality depends on what you give it
Compression Loop: repeated work becomes reusable infrastructure
Strategic Compression
Looks like: better AI workflow
Reality: team-level operating system
The model is rented.
The harness is owned.
Compression is the moat.
With massive ♥️ Gennaro Cuofano, The Business Engineer