The Map of AI Book
May 2026

A decade ago, I started mapping the economics of AI on a blog called FourWeekMBA. Back then, the map was small, and the cycle was slow. Three years ago, when ChatGPT crossed into the consumer mainstream, the map became a quarterly artifact. This year, the map redraws itself every time a four-billion-dollar lease closes. Earlier this month, it had seven layers. Today it has nine.
Two new layers earned their place. The first is the agentic harness — everything that surrounds a foundation model and makes it usable in production. The second is governance — the deliberate, paced release of frontier capability. Both layers were dormant a year ago. Both are now structural.
This is the workshop, compressed into a written piece. Four layers of analysis, in the Business Engineer format: the abstraction, the market map, the playbook, and what’s coming next.


For Premium Members:

Part One
The Abstraction — A Second Computing Revolution
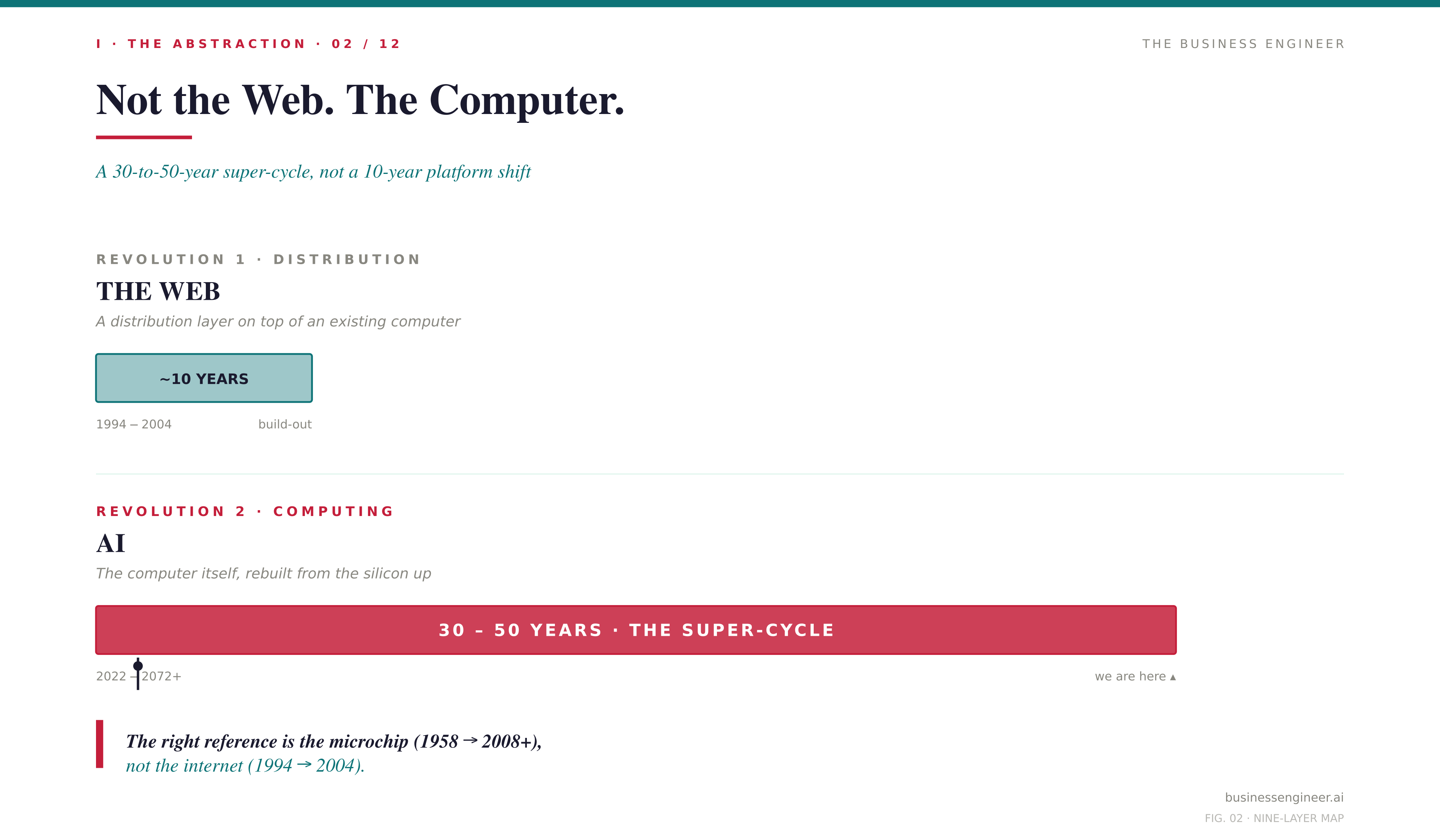
The mistake most analysts make is treating AI as a continuation of the web. It is not. The web was a distribution revolution layered on top of an existing computer. AI is the computer being rebuilt.
That single sentence reframes everything. It tells you why CapEx in 2026 will cross one trillion dollars and still leave the demand curve underserved. It tells you why memory contracts are sold out through 2027. It tells you why hyperscalers are signing nuclear power deals. It tells you why every frontier lab is also, quietly, becoming a chip company. The web revolution took a decade. The computing revolution that produced the web took fifty years. AI belongs to the second category.
The cleanest mental model I have for what is happening: the agent is becoming the computer. Until very recently your laptop was a deterministic machine — you typed a command, it executed deterministically. Right now, on millions of machines, an AI agent is sitting at the terminal, sandboxed, controlling the operating system through MCP, executing probabilistically on your behalf. In two or three years, the terminal-plus-agent collapses into a single object. The computer becomes probabilistic. The operator becomes the supervisor.

If you accept that frame, every other piece of the analysis falls into place. The trillion-dollar CapEx is not a corporate spending cycle — it is the cost of rebuilding the substrate. The geopolitical race is not over markets — it is over which civilization owns the new computer. The “bubble” question is not whether demand is real — demand is unconstrained — but whether physics can deliver supply fast enough.
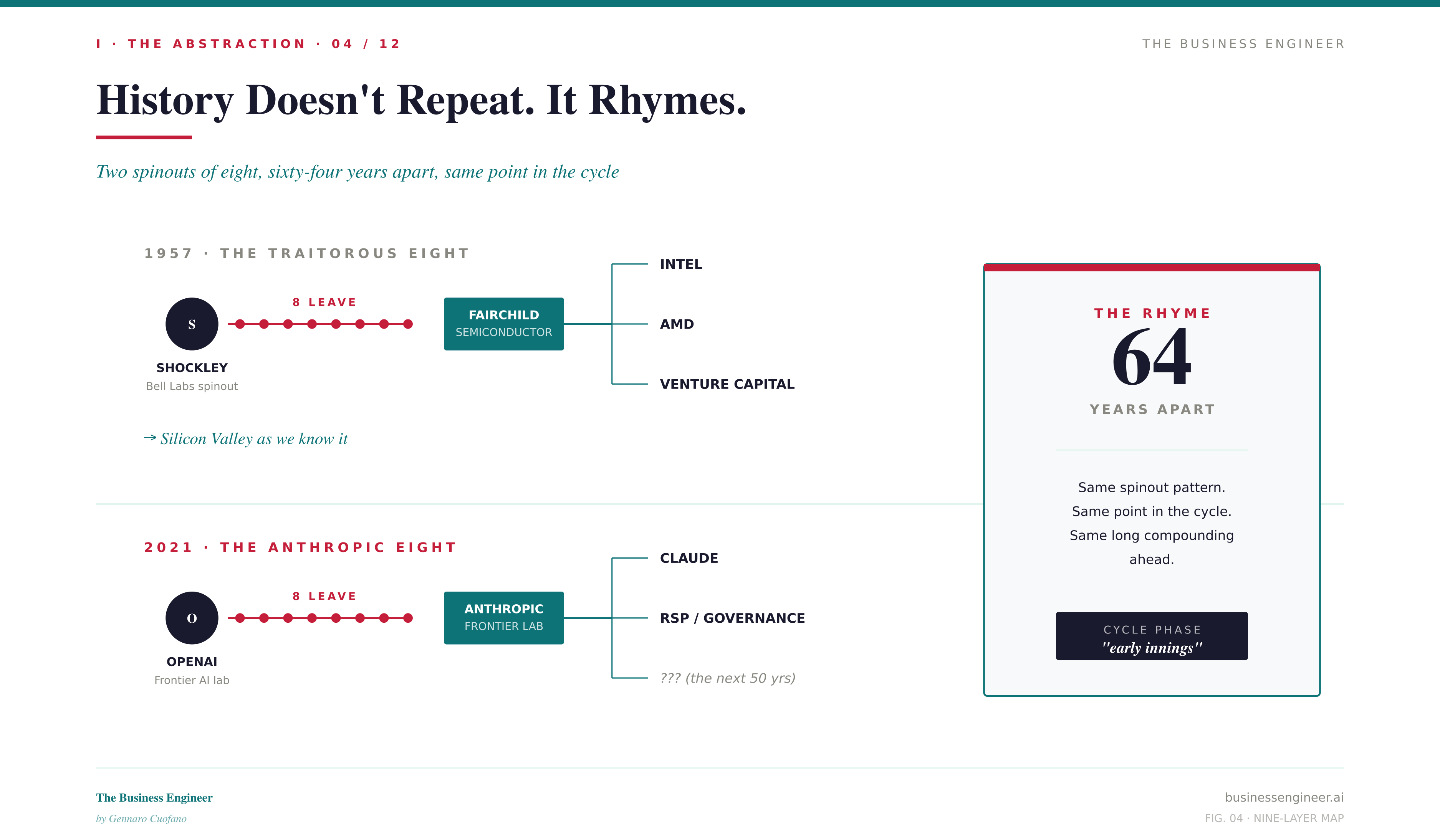
There is also a historical rhyme worth holding in mind. In 1957, eight researchers left Shockley Semiconductor and founded Fairchild — the Traitorous Eight. Their exit gave rise to Intel, the venture capital model, and the entire Silicon Valley. In 2021, eight researchers left OpenAI and founded Anthropic. We are watching the same pattern at the same point in the cycle, with the same long compounding ahead.
The Market Map — Nine Layers, Three Geometries, One Backbone
The Nine Layers
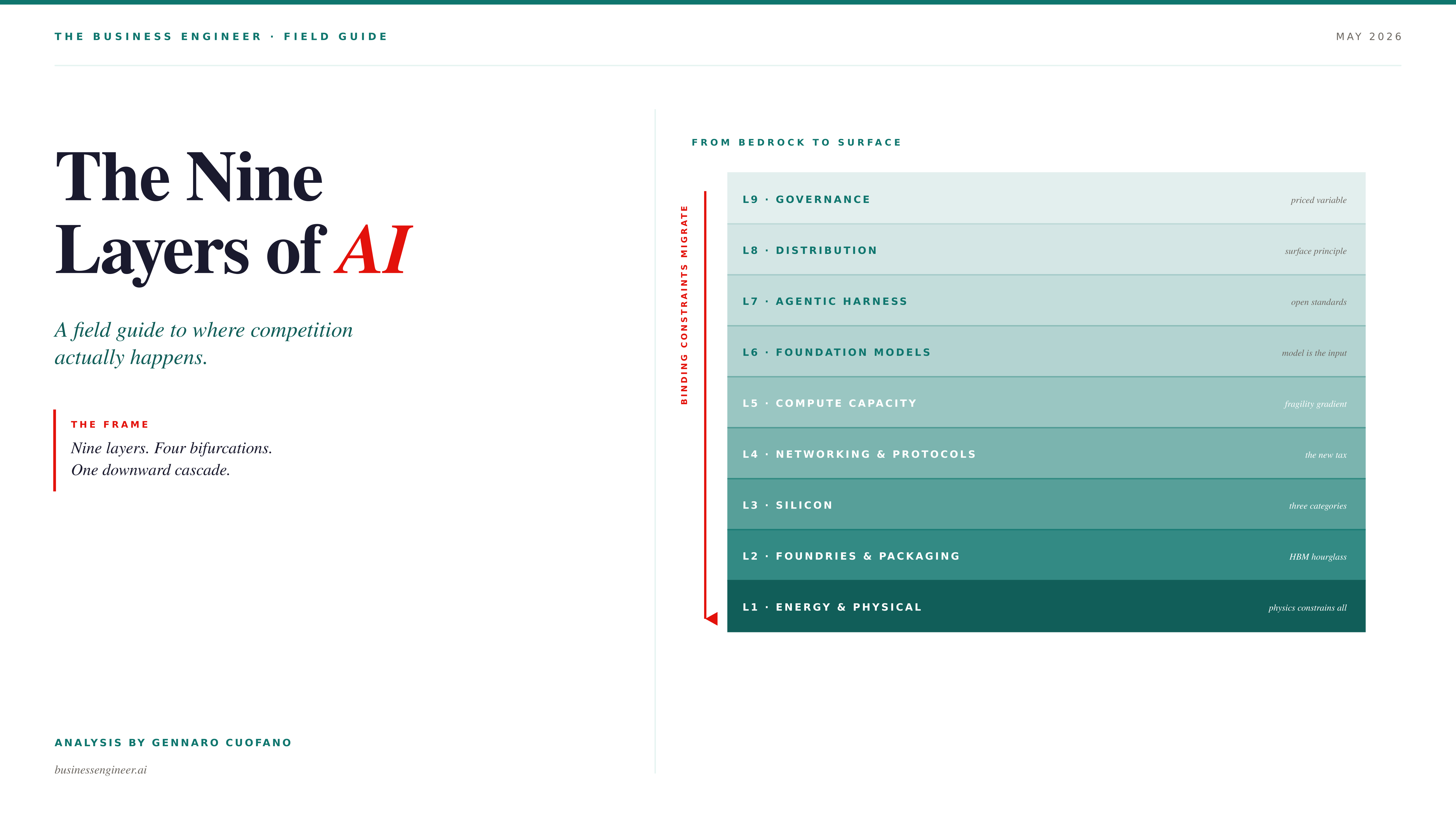
Every layer has a bottleneck. Not a soft bottleneck — a physical one. HBM4 is sold out through the second half of 2027 across the three suppliers that produce it (SK Hynix, Samsung, Micron). CoWoS advanced packaging at TSMC is allocated to NVIDIA first; merchant silicon teams negotiate for scraps. The U.S. grid is not designed for AI; only China’s grid is, because China invested in nuclear for non-AI reasons and now harvests the optionality. Lithography sits behind a single Dutch company.
The cleanest reading of the map is this: demand is unconstrained, supply is constrained everywhere. That is the inverse of what a classical bubble looks like. In a bubble, supply races ahead of demand and capital chases imaginary returns. In this cycle, capital is hitting a wall of physics. The bubble risk is not over-investment in compute — it is misallocation across layers when one bottleneck migrates to another faster than balance sheets can adjust.
The Trillion-Dollar Year
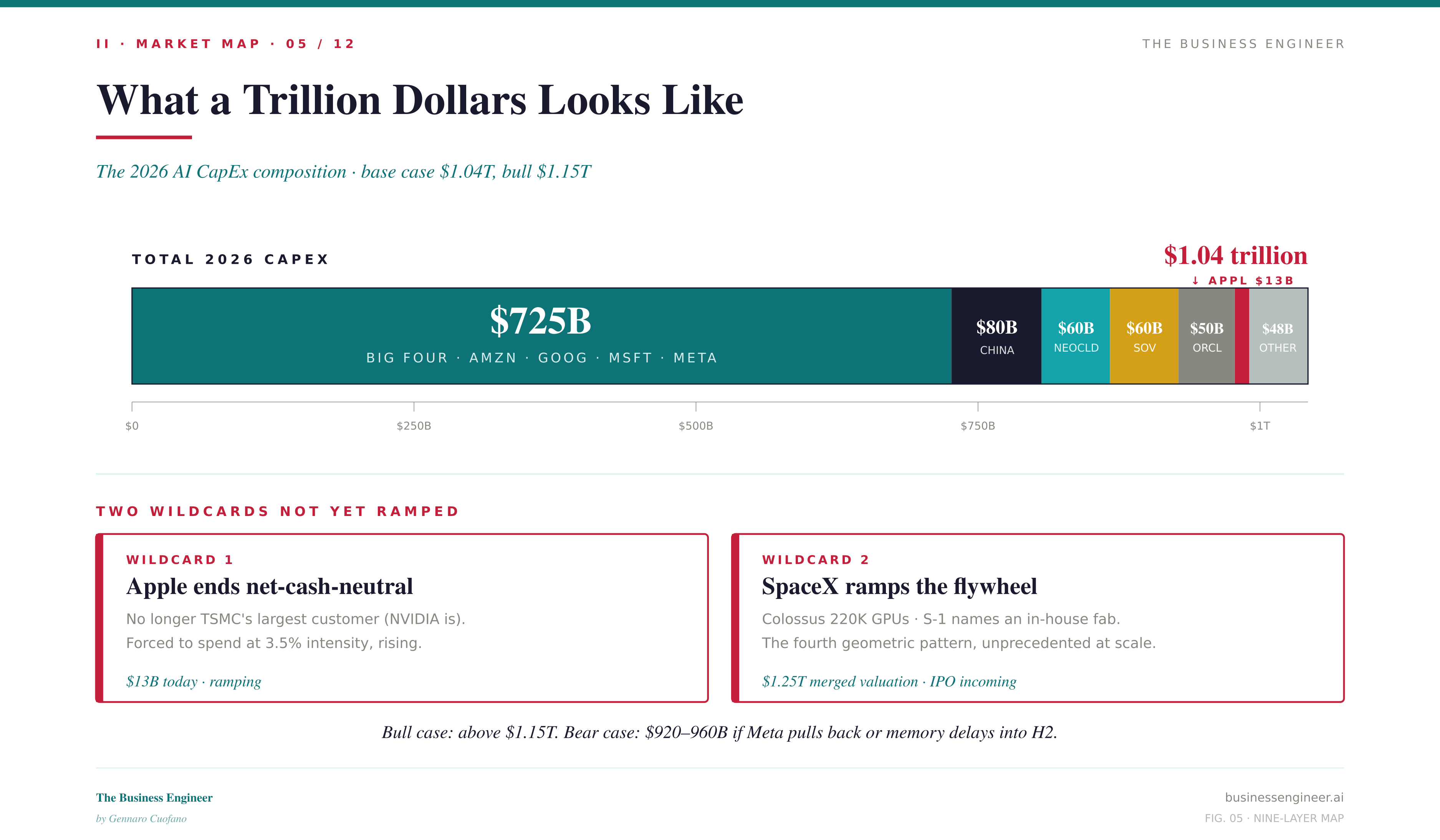
The 2026 CapEx number is roughly $1.04 trillion, distributed as follows: Big Four (Amazon, Alphabet, Microsoft, Meta) at $725B, China at $80B, neoclouds at $60B, sovereigns at $60B, Oracle at $50B, Apple at $13B, and the long tail at $48B. The Big Four alone are 3.7× their combined 2023 spend.
My base case is that 2026 closes well above the trillion-dollar mark — call it $1.10–1.15T — because two wildcards have not yet ramped. Apple is ending its decade-long net-cash-neutral posture; the new CEO will be forced to spend, because Apple is no longer TSMC’s largest customer (NVIDIA is) and the constraint is now on Apple’s ability to produce its own devices, not on its capital. SpaceX is the second wildcard — Colossus, the 220K-GPU cluster, plus a vertical-integration thesis that extends from launch (90%+ market share) to satellite (Starlink, 4M+ subscribers) to compute to, in the S-1, an in-house fab.
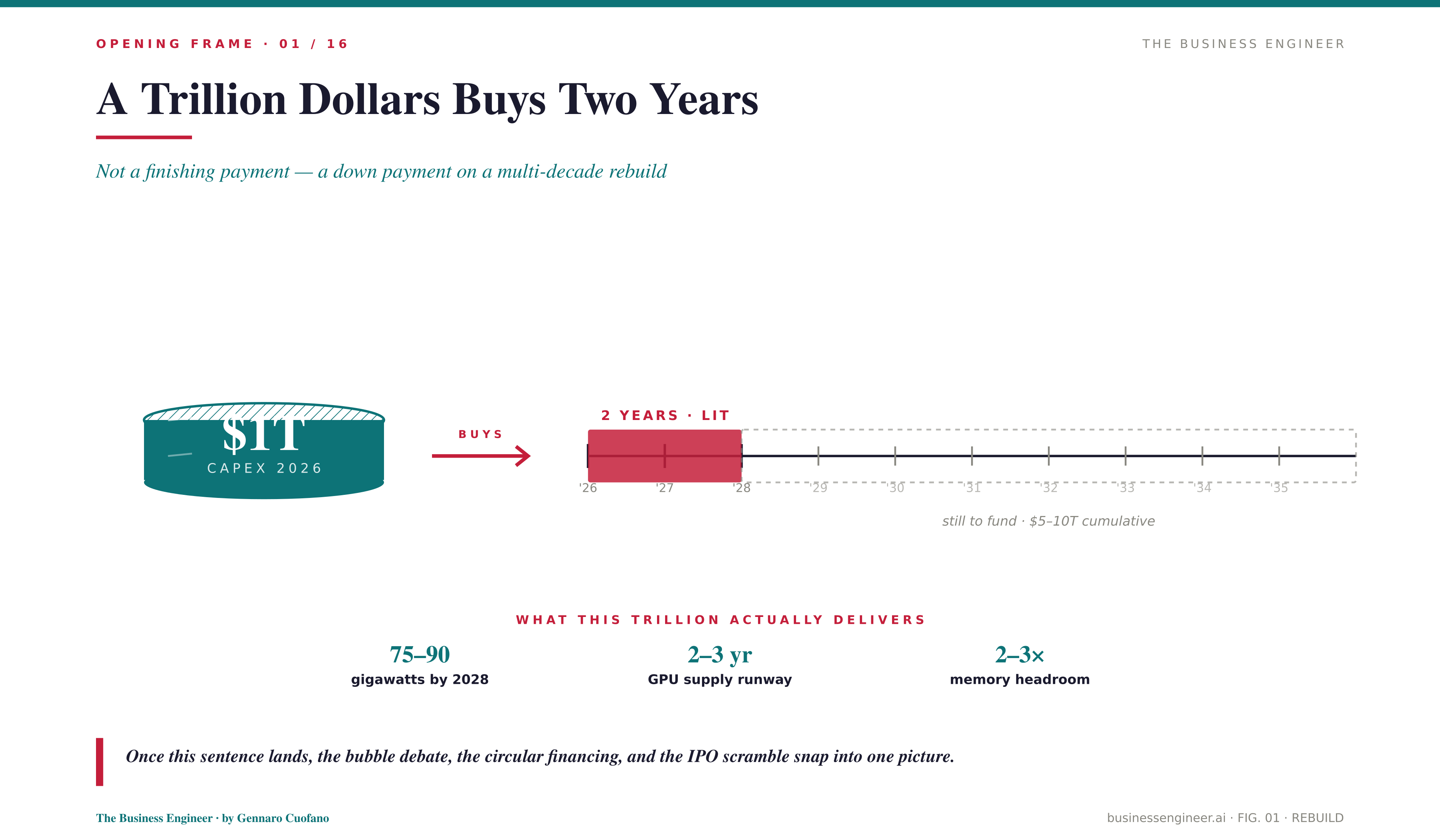
What does a trillion dollars buy in 2026? Roughly 75 to 90 gigawatts of new power capacity by 2028 — equivalent to the entire UK grid. Roughly 15 to 18 million GPU-equivalent units. A multiple of current HBM production. It buys enough supply to serve the next two to three years of demand, assuming no new demand surprise. The five-year cumulative need, on current trajectories, is closer to five to six trillion dollars.
Three Geometries (Plus a Fourth)
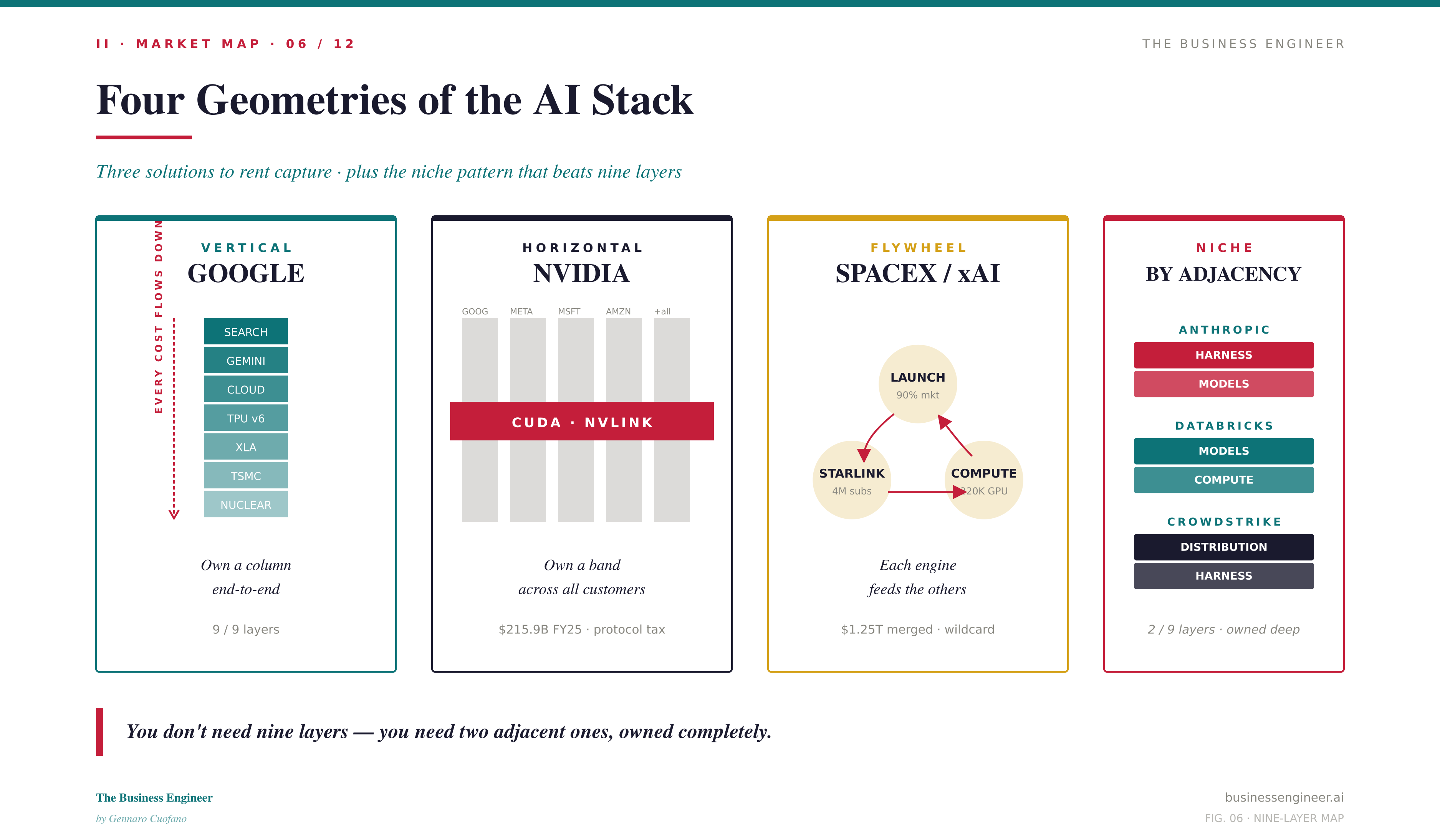
There are three solutions to the problem of “how do I capture rent across a layered stack” — plus a fourth that the niche players have found.
Vertical (Google). Own a column from foundry partner to user. Google has the TPU (sixth generation, deployed at scale, now sold externally for the first time in 2026), the XLA software stack, the Gemini model family, the agentic harness inside Gemini, and the distribution surface in Search plus Android. Every cost reduction at any layer flows through the entire column. The disadvantage: vertical columns are consumer-first by construction, and the enterprise battle requires different muscle.
Horizontal (NVIDIA). Own a band across all customers. Silicon (Blackwell, Vera Rubin), networking (CUDA, NVLink, Spectrum-X, Mellanox), systems (DGX, NVL72), inference software (NEMO, NIM), and an enterprise harness layer (AI Enterprise, Omniverse). NVIDIA is not a chip company — it is the connective tissue. Every GPU dollar drags a networking dollar; that ratio approaches parity at 100,000-GPU scale. The Mellanox acquisition is, in hindsight, the highest-return semiconductor deal of the past decade.
Flywheel (SpaceX). Multiple reinforcing engines that each feed the others. Launch capacity funds satellite buildout; satellites fund compute; compute funds the next launch. SpaceX does not fit the vertical or horizontal templates because the engines are not in the same stack. They are in adjacent stacks, and the cross-feed is the moat. This is the wildcard that made me redraw the map.
Niche by Adjacency. Anthropic owns foundation models plus agentic harness, deeply. Databricks owns compute capacity plus models for data-platform use cases. CrowdStrike owns harness plus distribution on the endpoint. The lesson is durable: you do not need nine layers — you need two adjacent ones, owned completely.
The Whale Backlog

The remaining performance obligations on the cloud books tell you where the demand is parked. Combined backlog across Microsoft ($627B), Oracle ($553B), Alphabet ($468B), and Amazon ($464B) is roughly $2.1 trillion. Of that, somewhere on the order of half traces back to two counterparties: OpenAI and Anthropic.
That circularity — hyperscalers invest equity in labs, labs commit compute credits back to those hyperscalers, hyperscalers book the revenue — is real. The honest read is that it works as long as the labs grow into the obligations. The required rate of growth: 20–30× over three years. OpenAI from ~$5B ARR today to $100–150B. Anthropic from ~$9B (some say $30B+ projecting forward) to $180–270B. No software company in history has done 20× in three years. Both labs need to do it simultaneously.
That is what makes the upcoming IPOs (SpaceX, OpenAI, Anthropic) the most important test of the entire cycle. The private market can carry the assumption. The public market will price it.
The China Parallel Stack

Export controls did not slow China — they forced China to build an indigenous full-stack from silicon to distribution. Huawei Ascend on SMIC 7-nm fabrication, CXMT and YMTC memory, MindSpore and CANN as the software layer, DeepSeek and Baidu and Alibaba at the model layer, domestic distribution platforms on top. The capability gap to the U.S. frontier is three to seven months. The sovereignty gap is zero — full end-to-end independence.
This is why the governance layer matters geopolitically. When Anthropic and OpenAI release their most capable models on a paced, capability-gated cadence, the side effect — possibly the intent — is that Chinese open-source labs lose their distillation source. Open-weight Chinese models stayed near the frontier in part because they could distill from the U.S. frontier through API. Pace the frontier release, and you cap the open-source ceiling.
The Playbook — How to Read the Map
Cascades, Not Stacks
The stack metaphor is useful for inventory but misleading for dynamics. The real action is in cascades — how a shift in one layer propagates to every adjacent block.
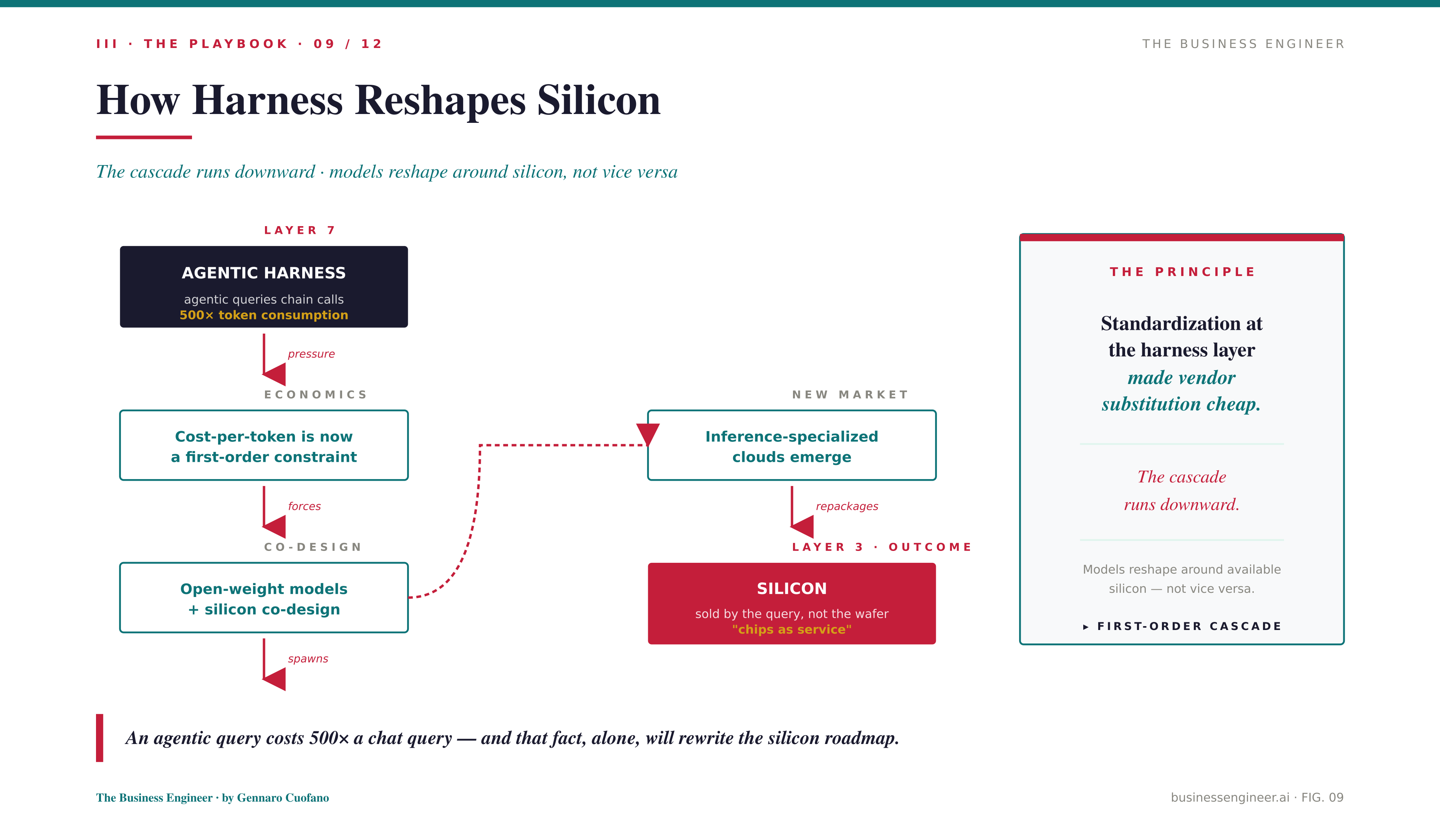
Take the most important cascade flowing downward right now, from harness to silicon. Agentic queries consume roughly 500× the tokens of single-turn chat queries because every agent call chains multiple model invocations. That makes cost-per-token a first-order constraint. The economics of inference at agentic scale demand cheaper inference at massive volumes. That pressure pushes open-weight models to co-design with silicon. Inference-specialized clouds emerge. Silicon stops being a component and becomes a service, priced by the query rather than by the wafer.
Or take the cascade flowing upward through the financing stack. NVIDIA leverages GPU allocation plus financing to lock in AI labs. AI labs consume compute and ramp up revenue commitments back to the clouds. Clouds book backlog. Backlog supports more capex. If labs fail to monetize, cloud backlog is impaired, NVIDIA demand drops, the cycle reverses. Every dollar in the system is someone else’s revenue and someone else’s cost.
Two Structural Breaks

Two events in the past twelve months were unthinkable eighteen months ago.
Microsoft–OpenAI exclusivity ends. OpenAI can now serve from any cloud. Azure loses its only moat in model serving — the $627B Microsoft backlog is suddenly exposed to multi-cloud risk. Microsoft’s response: ramp CapEx urgently to lock down compute, accelerate the development of its own frontier model in-house, and try to make Copilot the GitHub-of-AI-coding before Claude Code finishes eating that lunch. The honest read on the supposed Microsoft cancellation of Claude Code licenses: it is not about token cost — it is about not letting a competing harness eat your enterprise developer relationship.
Apple ends net-cash-neutral. For the first time in the modern era, Apple will hold more debt than cash. CapEx intensity actually declines as a share of revenue (5% to 3.5%), but absolute spend rises. The strategic problem for Apple is not financial — Apple has plenty of cash. The strategic problem is that NVIDIA, not Apple, is now TSMC’s largest customer. Apple has lost the pace-setting position it held for fifteen years. In a near future where consumers want multiple devices to run multiple local agents, Apple may not be able to produce enough chips to meet its own demand. That is the supply-side risk Tim Cook’s successor was hired to fix.
Hyperscalers Become Utilities

The bottom of the stack used to be compute. Now it is substations. Microsoft is restarting Three Mile Island for 835 MW. Amazon has signed Talen for nuclear plus gas portfolios totaling 1,920 MW. Meta is building Project Hyperion, a 2-GW single-campus data center, the largest ever. Google is investing in Oklo small modular reactors. These are not data center deals — they are utility deals. A hyperscaler in 2026 is, structurally, a power company that happens to sell tokens.
The corollary: power geography becomes destiny. Pennsylvania for nuclear-plus-coal baseload. Texas, the Nordics, and Quebec for cheap stranded hydro and nuclear. The Gulf states for unlimited solar plus gas, backed by sovereign wealth — Gulf SWFs collectively hold roughly $2.5T and are pivoting hard from oil to AI infrastructure. NEOM’s smart-city budget was cut 58% and redirected to AI compute. Self-generation through on-site SMRs is the wildcard for those who cannot wait for grid permitting.
The Memory Crunch
If you want a single price signal that tells you the cycle is real, look at HBM contract prices. They moved 95% quarter-over-quarter. The oligopoly is three players and the production is allocated through 2027 to a single buyer with priority. Every consumer-electronics company in the world will pay a DRAM premium as collateral damage. This is what supply-bound demand looks like in a chart.
The memory crunch will persist for years because semiconductor capacity does not scale on annual cadence — it scales on five-to-ten-year cadence. The trillion dollars of 2026 CapEx buys you the foundation for 2027–2028 supply. To serve 2029–2030, you need another trillion in 2027.
Capital Equals Physics
The simplest mental model for this market: capital equals physics. As long as physics has slack, capital compounds. The moment physics binds — and it binds now, at every layer — capital stops being the variable. Permitting becomes the variable. Lithography slots become the variable. Substrate yields become the variable.
The IPO window is the public test of how this rebalances. SpaceX, OpenAI, and Anthropic going public in the next eighteen months will tell us whether the market accepts the capex-equals-physics frame and prices accordingly, or whether the public markets impose a different rate of return on the labs than the private markets have. My base case is the former. The bear case is the latter, and the bear case is real.
What’s Next — The 2027–2028 Inflection
A few patterns I expect to harden over the next eighteen to twenty-four months.
The four scaling paradigms collapse into recursive learning. Right now, four scaling laws stack: pre-training scaling, post-training reasoning, test-time compute, and agentic loop scaling. They run in parallel silos. The next breakthrough — and Andrej Karpathy joining Anthropic is the signal — is recursive self-update: models that update their own weights from agentic feedback. If that lands, you get continual learning across all four scaling laws simultaneously. That is the architecture that pushes us past the current quality plateau toward something most people would recognize as AGI.
Agentic enterprise becomes the default. Two vendors, one protocol layer. Claude for reasoning, Codex for automation, both interoperating through MCP and AGENTS.md. MCP plus AGENTS.md are becoming the HTTP-and-HTML of agents. Proprietary walled gardens are losing; standards are winning. Every enterprise will run a two-vendor harness by end of 2027.
Distribution becomes the consumer endgame. Apple is embedding Gemini into 2.2 billion devices. Google AI is becoming Google search for billions of users who will never know it changed. Meta needs the AR glasses bet to land because that is where the consumer agent sits on the body, not on the desk. ChatGPT consumer share peaks; super-app dynamics take over.
The China stack completes. By 2027, every layer of the Chinese AI economy will be domestic, with capability roughly six months behind the U.S. frontier and full sovereignty. The strategic question is no longer whether the bifurcation happens — it has happened — but whether the two stacks remain interoperable at the protocol layer or fully decouple.
Sovereign AI becomes a permanent third demand category. Beyond hyperscale and enterprise, sovereign compute is now structural. Every nation-state with the means is building national capacity. Every sovereign program buys NVIDIA at the top of the stack because there is no alternative at that scale.
Networking eats economics. At 100K+ GPU clusters, networking cost approaches GPU cost. The Mellanox acquisition becomes the most consequential deal NVIDIA ever made. Every model release will be benchmarked against the networking architecture it requires to serve.
Physical AI emerges as the third value region. Infrastructure (silicon, compute, energy) keeps the highest margins for the longest time. Agentic applications (models, harness, distribution) get the fastest growth and the most competitive intensity. Physical AI (robotics, autonomous, AI-RAN, industrial) is the earliest stage with the largest TAM and a thirty-year deployment horizon. Every humanoid robot and every autonomous vehicle and every AI-RAN telecom defaults to NVIDIA’s reference architecture. The cascade flows.
The TSMC question is the choke-point of the choke-points. TSMC is the constraint that everything else routes through, and it is not ramping CapEx as fast as the rest of the system wants. Read that as discipline, not weakness — TSMC remembers the early-2000s telecom CapEx hangover and is deliberately holding the line. But it means the supply ceiling is set in Taiwan, with all the geopolitical exposure that implies.
Key Takeaways & Mental Models
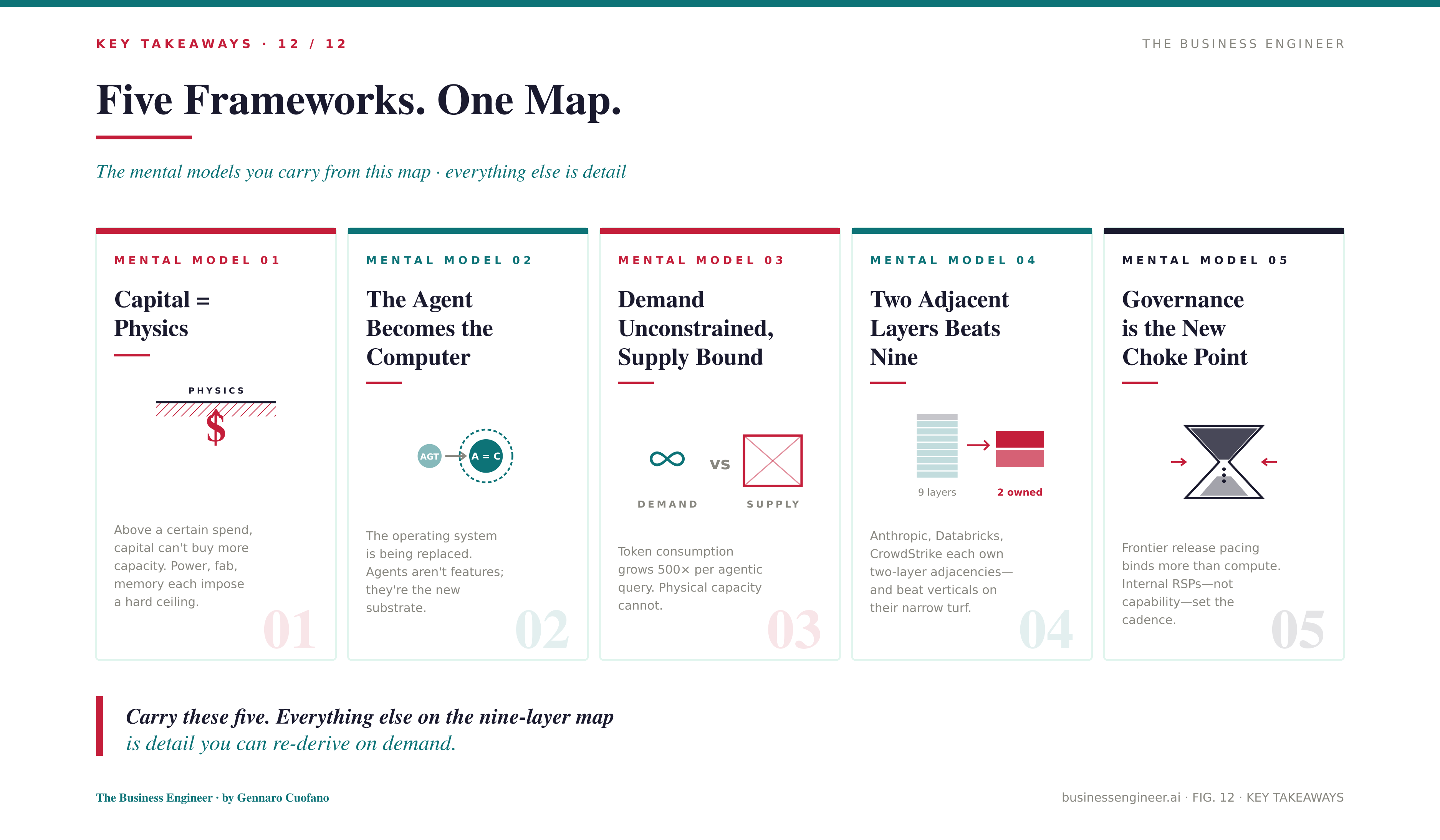
Five frameworks to carry from this map into the next twelve months of decisions.
Capital = Physics. Capital flows where physics has slack. Capital halts where physics binds. In 2026 every layer of the AI stack has hit a binding physical constraint, so capital’s role flips from accelerator to allocator.
The Agent Becomes the Computer. The probabilistic agent merges with the deterministic operating system within three years. Every product strategy should answer one question: what does this look like when the agent is the computer, not a feature inside it?
Demand is Unconstrained, Supply is Bound Everywhere. The bubble frame is wrong because the cycle is supply-bound, not demand-bound. The real risk is misallocation across the nine layers as the binding constraint migrates faster than balance sheets can adjust.
Two Adjacent Layers Beats Nine. The niche-by-adjacency pattern — Anthropic on Models+Harness, Databricks on Compute+Models, CrowdStrike on Harness+Distribution — is the winning posture for anyone who is not Google, NVIDIA, or SpaceX. Pick two adjacent layers, own them completely, ignore the rest.
Governance is the New Choke Point. Paced release of frontier capability is now a deliberate competitive lever, not just a safety posture. It caps open-source distillation, it differentiates enterprise positioning, and it shapes the geopolitical balance between the two stacks.
Part Two - The AI Capex Dynamics
A trillion dollars in capex this year buys roughly two years of AI supply.
That sentence does almost all the analytical work in this piece. Once it lands, the noise about circular financing, the bubble debate, the off-balance-sheet vehicles, and the IPO scramble all snap into the same picture. We are not in a cloud-capex cycle. We are not in a web-investment cycle. We are in a computer-rebuild cycle, and the physical infrastructure required to rebuild a computer at planetary scale costs more than the public market is yet prepared to price.
Three layers of analysis: the abstraction (why this is a second computing revolution, not a web cycle), the market map (the financing machine that funds the rebuild), the playbook (three capital cascades and what to watch in each), and what comes next (the wildcards that will push 2026 capex past the trillion-dollar mark and the IPO window that will test the whole thesis).