The Subsidized AGI Economy

SemiAnalysis just published a sharp thread of primary research on AI subscription economics.
Their team bought one of each Anthropic and OpenAI subscription plan, ran long-horizon coding tasks until the weekly limits were exhausted, and back-calculated what each subscription actually delivers at API-equivalent pricing.
The headline numbers — up to $14,000/month of usage on a $200 ChatGPT Pro plan and $8,000/month on Claude Max 20x — are 4× to 7× more generous than the widely-circulated ~$2,000/month rule of thumb.
They then modeled subscription gross margin under the assumption that the underlying API carries a 75% margin.
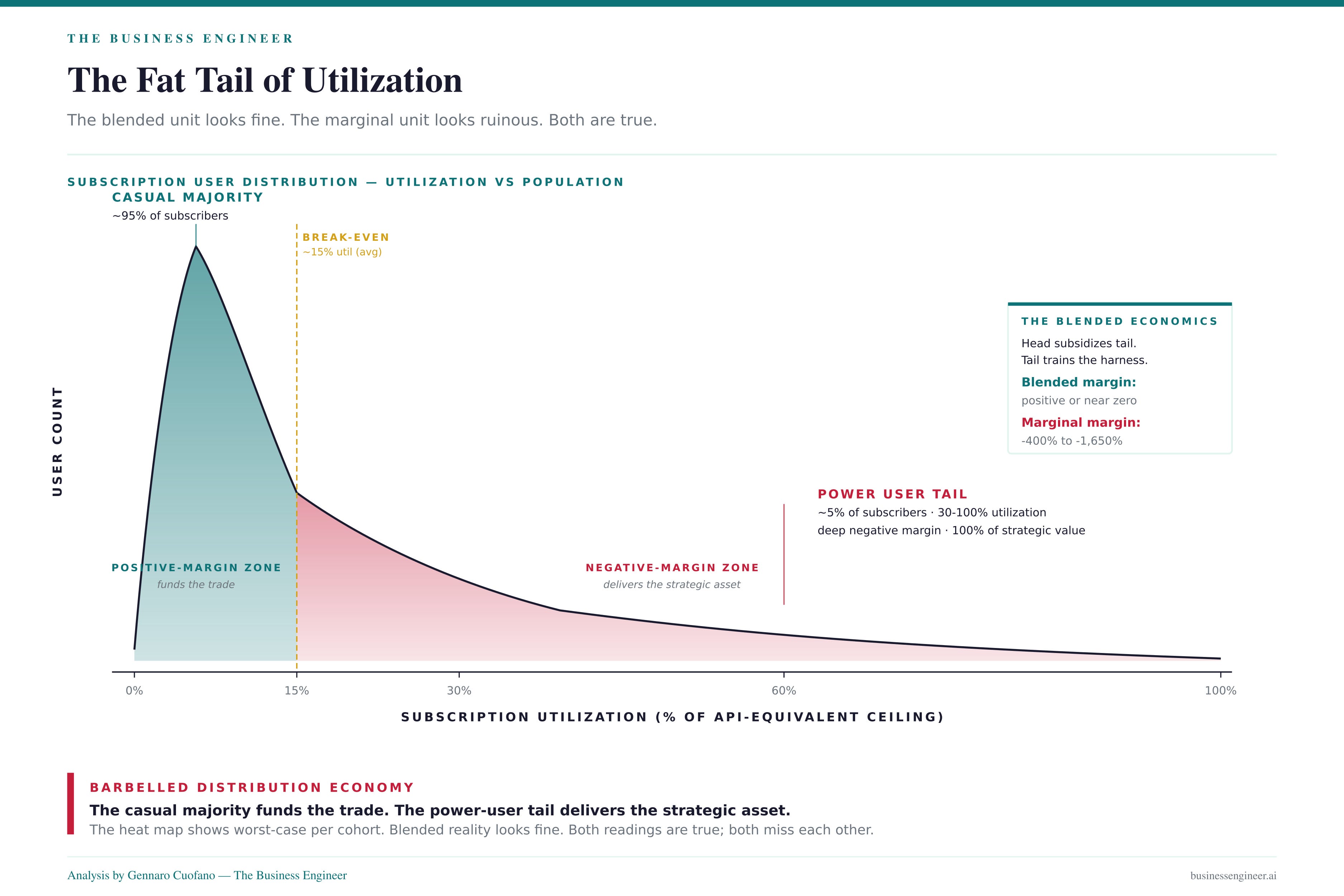
The result is the heat map circulating across timelines this week: ChatGPT Pro 20x runs -1,650% margin at full utilization, Claude Max 20x runs -900%, and every tier crosses into negative territory once a single power user pushes past roughly 10–20% utilization.
Their conclusion: openly nerfing subscriptions is off the table because public backlash is asymmetric to the savings, so the labs will instead withhold new features and models from subscription plans — with the explicit prediction that Mythos may end up being API-only.
We agree with all of this. The experimental approach is clean primary research, the heat map is the right framing of the data, and the policy prediction — vintage withholding rather than usage caps — is the correct structural answer to the subsidy problem.
This piece picks up where SemiAnalysis stopped. The same charts are already being read by a second wave of commentary as “AI subscriptions are a bubble” — confusing accounting margin with strategic position. The deeper structural read goes the other direction: the negative margin is not a leak, the subscription is doing three pieces of strategic work simultaneously, and the timeline on which this trade pays off is the timeline of token deflation, not the timeline of quarterly earnings.
Three things the bubble framing misses, and SemiAnalysis touches but does not fully unpack:
The negative margin is not a leak. It is a procurement budget. The labs are not pricing the product; they are buying an input that is not for sale anywhere else: agentic workload signal at the frontier of difficulty.
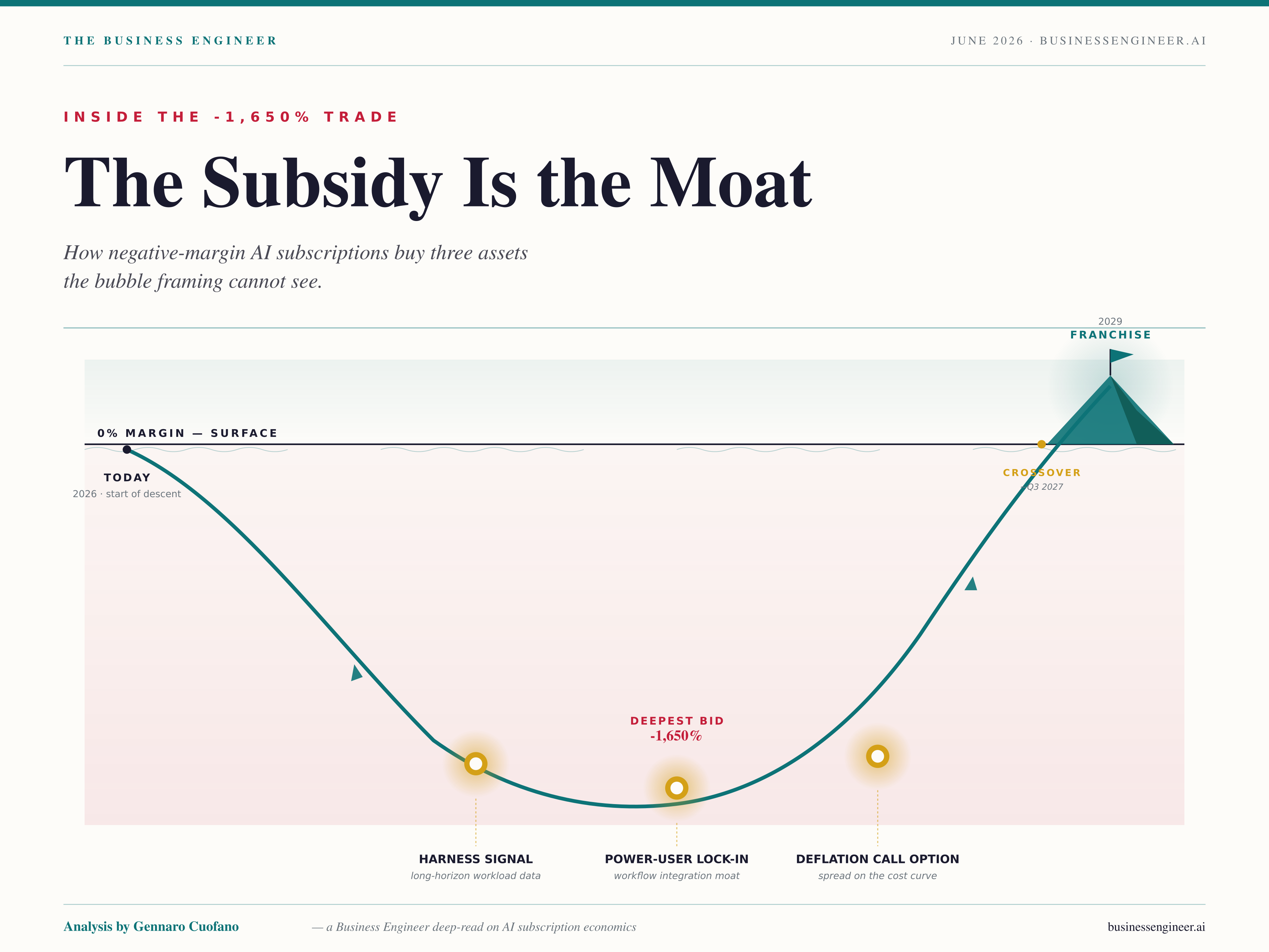
The subscription is a call option on token deflation. Lock in $200/month today against an API-equivalent value that compounds downward by an order of magnitude per year, and the same plan that prints -400% margin today prints +50% margin in 24 months — without changing a single line item.
The power user is the moat. A user willing to pay $200/month and burn through $14K of equivalent usage on long-horizon coding tasks is not a churn risk. They are the substrate on which the next frontier is trained, and the only seat from which the deflation curve becomes ownership.
This is not a bubble. It is the harness training auction — the most important strategic transaction in AI right now, and the one nobody on the surface reading is pricing correctly.
The Three-Asset Subsidy
The subscription is not one product. It is three assets bundled at a single price.
Asset 1: Harness training signal
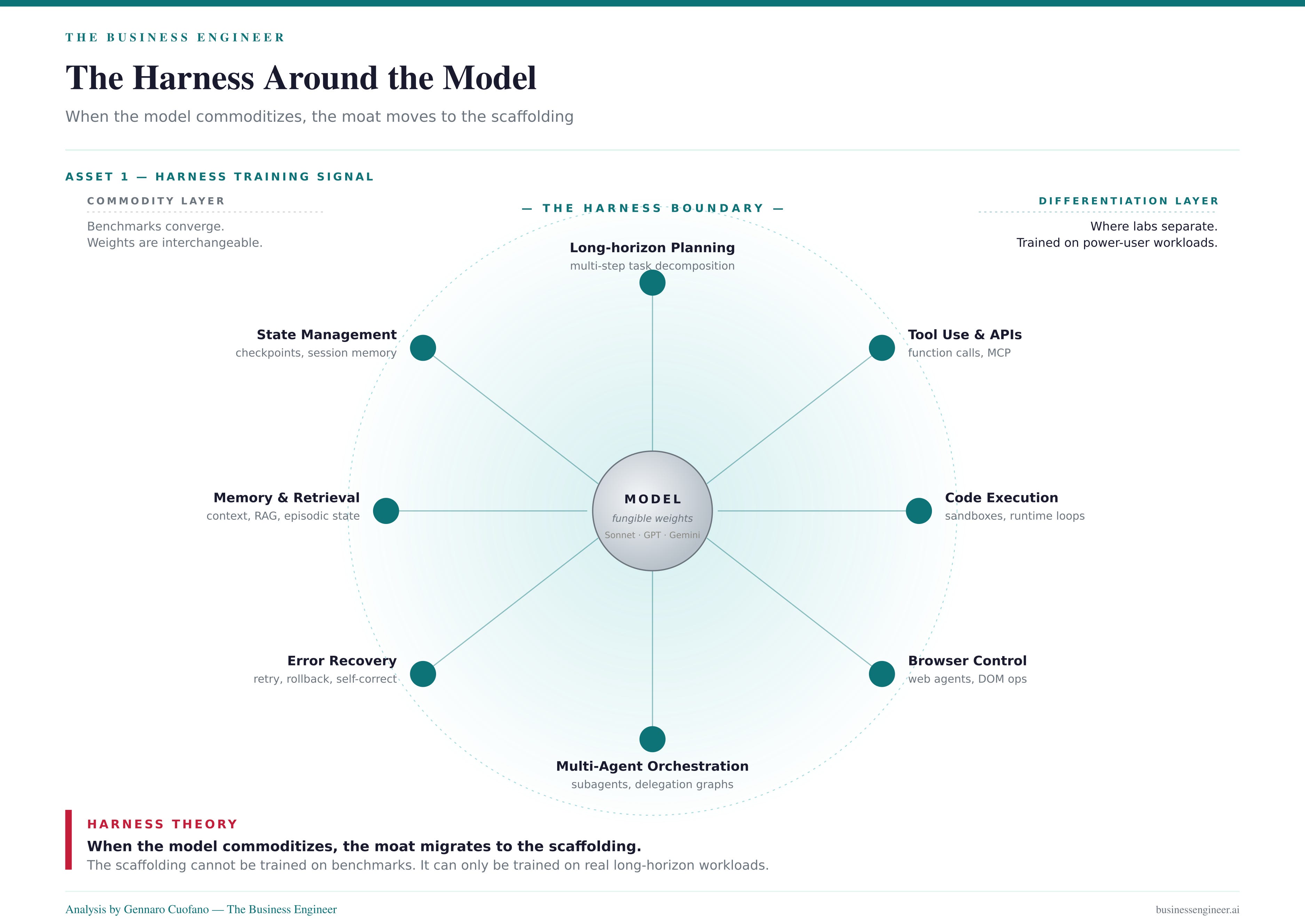
The frontier moat has shifted. Model weights are increasingly fungible — Sonnet, GPT, Gemini, and Grok cluster within a few points on benchmarks that mattered last year. What separates them now is the harness — the agentic scaffold around the model: tool use, planning, memory, error recovery, multi-step orchestration, browser control, code execution.
This is what Harness Theory predicts: when the model commoditizes, the moat migrates to the scaffolding. And the scaffolding cannot be trained on benchmarks. It can only be trained on real long-horizon workloads — the kind a $200/month power user runs for 14 hours a day, four weeks a month.
Asset 2: Power user lock-in
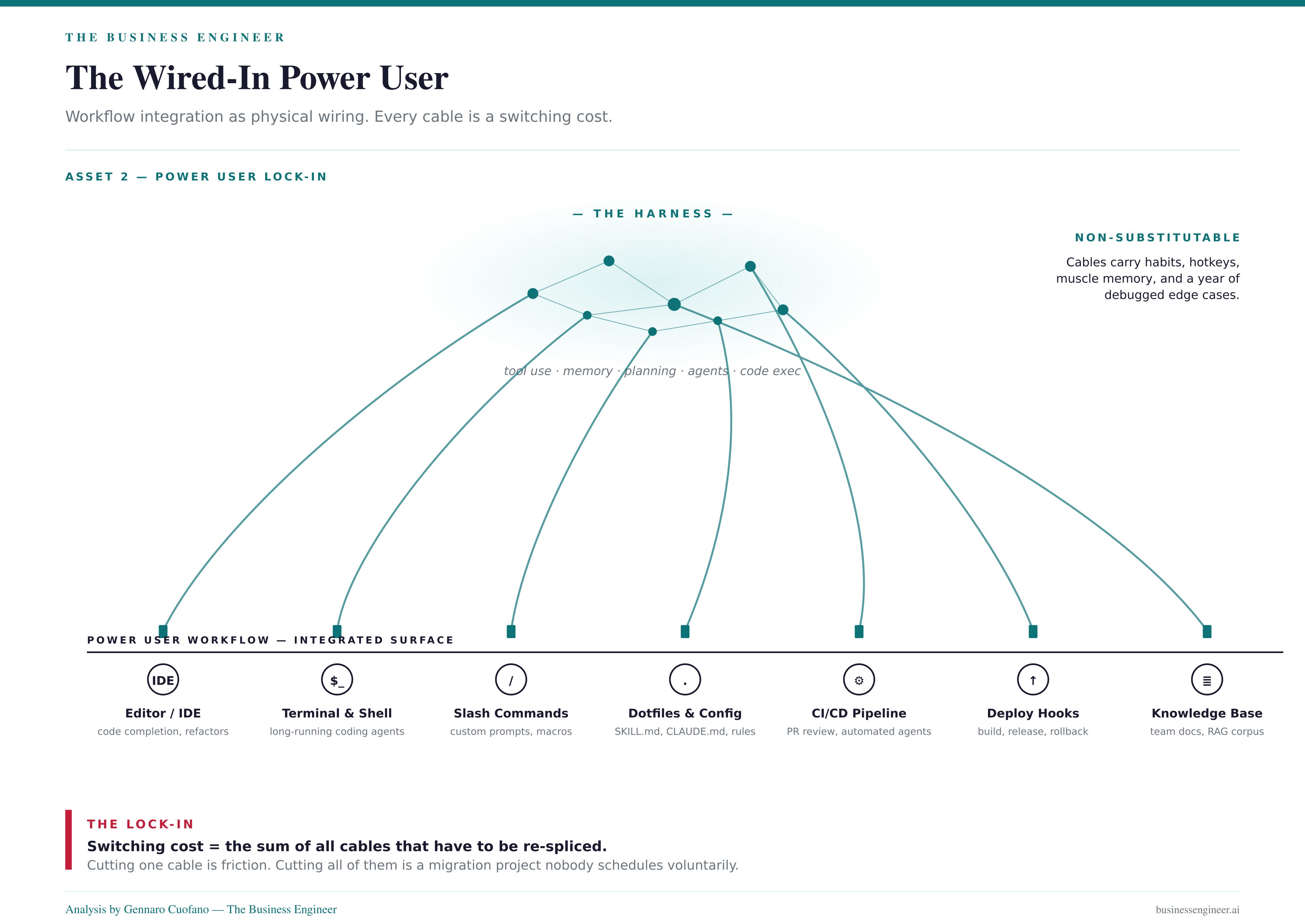
Not the casual user. The casual user pays $20 and uses 2% of capacity — they are the cross-subsidy. The asset being bought is the high-utilization user: the developer who has wired their entire workflow around Claude Code or Codex CLI, who has internalized the harness, who pays $200/month and would scream if it disappeared. These users are non-substitutable in three directions: workflow ($200/mo plus a year of muscle memory), API equivalence (their usage maps to $14K/month, which they will not pay), and competitor switching (the harness is sticky in a way the model is not).
Asset 3: Token deflation call option

This is the asset nobody is pricing. Token prices have fallen ~10× per year for two years running. Opus-class capability that cost $75/MTok in 2024 is delivered in 2026 for roughly $7-15/MTok depending on routing. If the trend holds — and there is no structural reason to expect it not to — the $14,000 of API-equivalent value being delivered today on a $200/month plan becomes $1,400 next year. The subscription price is locked. The cost of delivering it is collapsing. The trade is geometric on the cost side, linear on the revenue side, and the labs are sitting on a multi-year barbell.
The bubble framing sees -1,650% margin and reads collapse. The structural read sees -1,650% margin and reads purchase order: the labs are spending negative margin today to acquire the three assets that determine who wins when the deflation curve crosses zero.
The Math of the Trade
The heat map exposes a structural asymmetry that deserves attention.
The break-even utilization thresholds are not symmetric across vendors:
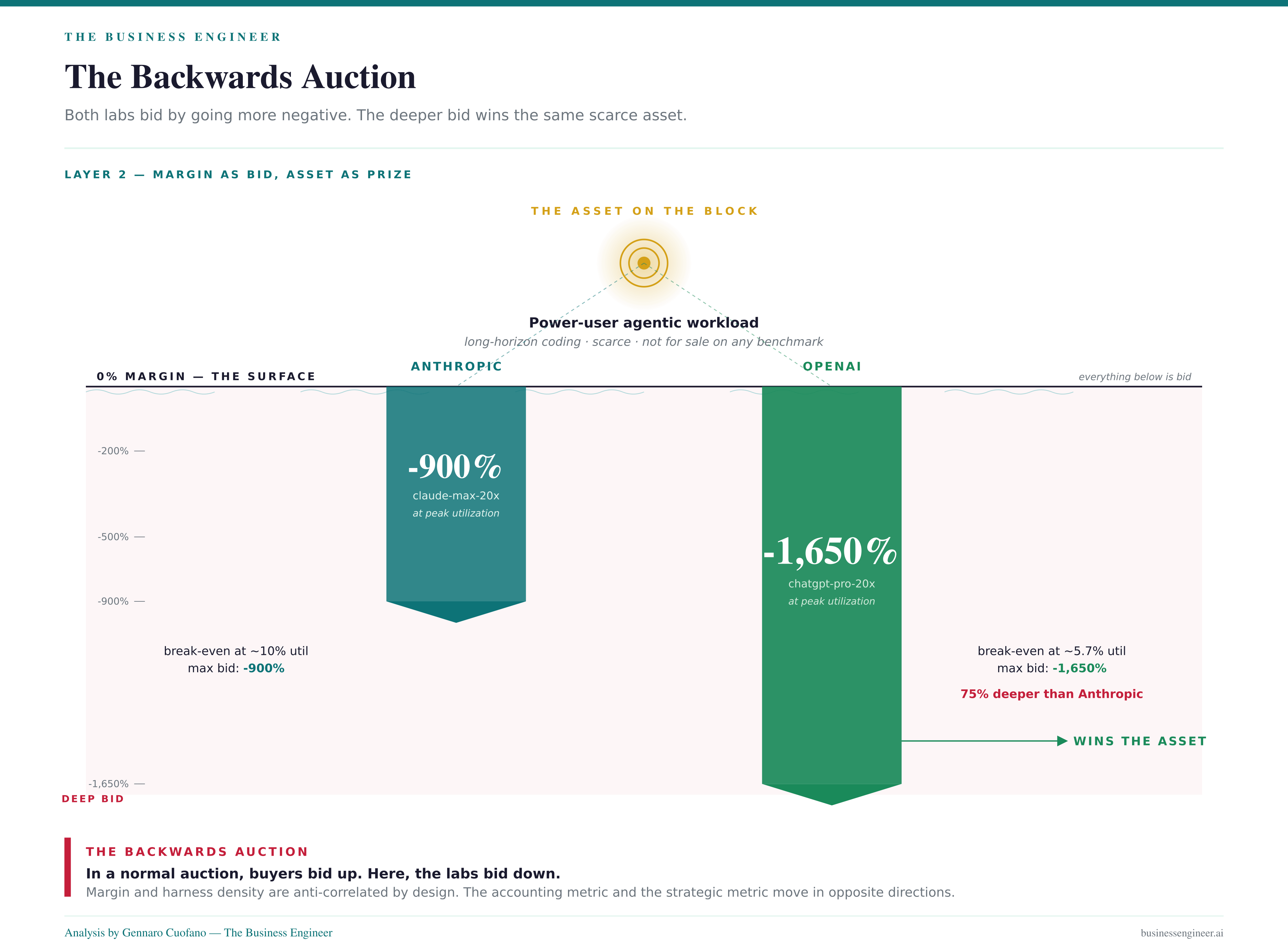
OpenAI is running a more aggressive subsidy curve. ChatGPT Pro 20x breaks even at almost half the utilization of Claude Max 20x, and bleeds nearly 2× the margin at full utilization. This is not noise.
This is OpenAI declaring that the harness signal is worth more to them — either because they are further from the agentic frontier and need catch-up data, or because their consumer surface is the strategic priority and Anthropic’s enterprise tilt allows it to be more disciplined with consumer subsidies.
Either reading is structurally meaningful. The dollar amounts are also strategically meaningful. ChatGPT Pro 20x delivers $14K of equivalent usage to Claude Max 20x’s $8K — a 75% premium on the subsidy budget at the same sticker price. OpenAI is putting more chips on the table per power user, which means OpenAI is betting harder on the three-asset thesis than Anthropic is.
A useful frame: this is a backward auction. In a normal auction, buyers bid up. Here, the labs bid down — the more aggressive they get with subsidies, the worse their unit economics look on the surface, but the more harness signal and lock-in they win. The accounting metric (gross margin) and the strategic metric (harness density) are anti-correlated by design. Treating one as a proxy for the other is the categorical error driving the bubble narrative.
What the math actually says: at current utilization distributions — which are still mostly low-intensity casual usage with a long tail of power users — blended margins are likely positive or near zero. The heat map shows the worst case per cohort, not the blended reality. The labs are running a fat-tail trade where the casual masses cross-subsidize the power users, and the power users deliver the strategic asset.