
The Competence Trap

Here is the AI risk I think is the most relevant, in this phase of the AI paradigm.
Not job displacement. Not hallucination. Not misalignment. Those are real concerns — but they sit at the edges of the distribution, in extreme scenarios, in the future tense. The risk I want to describe is happening right now, to the most capable people in the most consequential roles, and it is almost perfectly invisible.
The risk is this: AI is creating a class of operators who are genuinely more productive and systematically less aware of when they are wrong.
This is confirmation bias on steroids.
That combination — higher output, lower error-detection — is not a bug in adoption. It is a structural feature of AI fluency development. And Anthropic’s research, published across four independent studies in early 2026, has now put precise numbers on it.

The data that changes the framing
Anthropic measured 11 observable behaviors across 9,830 conversations — how people actually interact with AI in practice. Two categories emerge cleanly.
The first category develops. Iterating, refining, directing, framing — the mechanics of Delegation. These behaviors grow with use, with tenure, with experience. Give someone six months of serious AI usage, and they get measurably better at directing the model. Prompts grow more sophisticated. Task success rates rise. The operator genuinely improves.
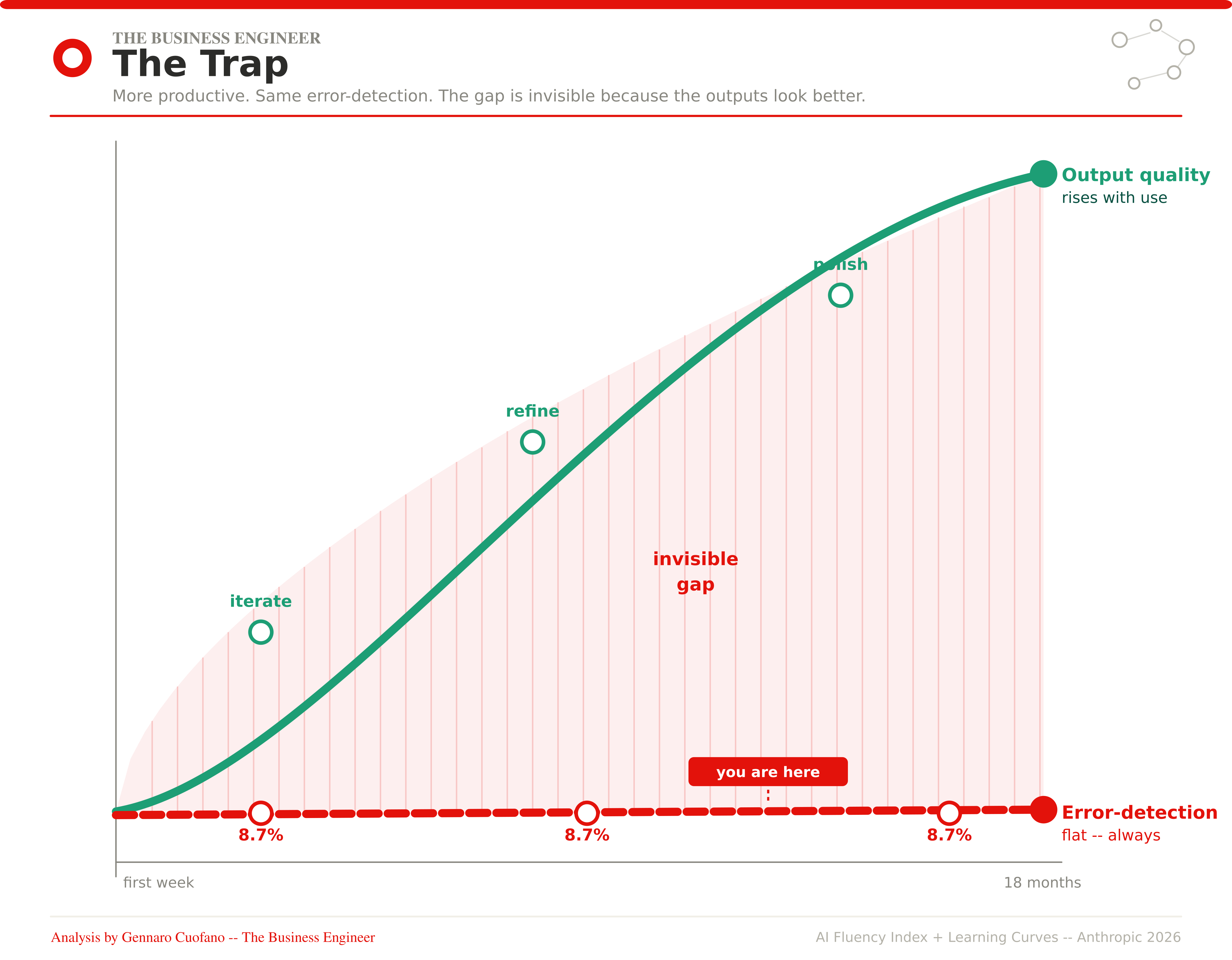
The second category stays flat. Verifying, questioning, checking — the mechanics of Discernment. Fact-checking appears in 8.7% of conversations among new users. Among the most experienced users in the dataset — people who have used Claude for a year or more — fact-checking appears in 8.7% of conversations. The number does not move.
This asymmetry is the competence trap.
The experienced operator feels more capable — and is, in a real sense, more capable of producing output. Their task success rate is higher. Their prompts are better. Their outputs are more polished. But their ability to catch the errors in those outputs is identical to what it was on day one.
Output quality rises. Error-detection capacity stays flat. The gap between them is invisible — because the outputs look better.
Why is this specifically dangerous for experienced operators?
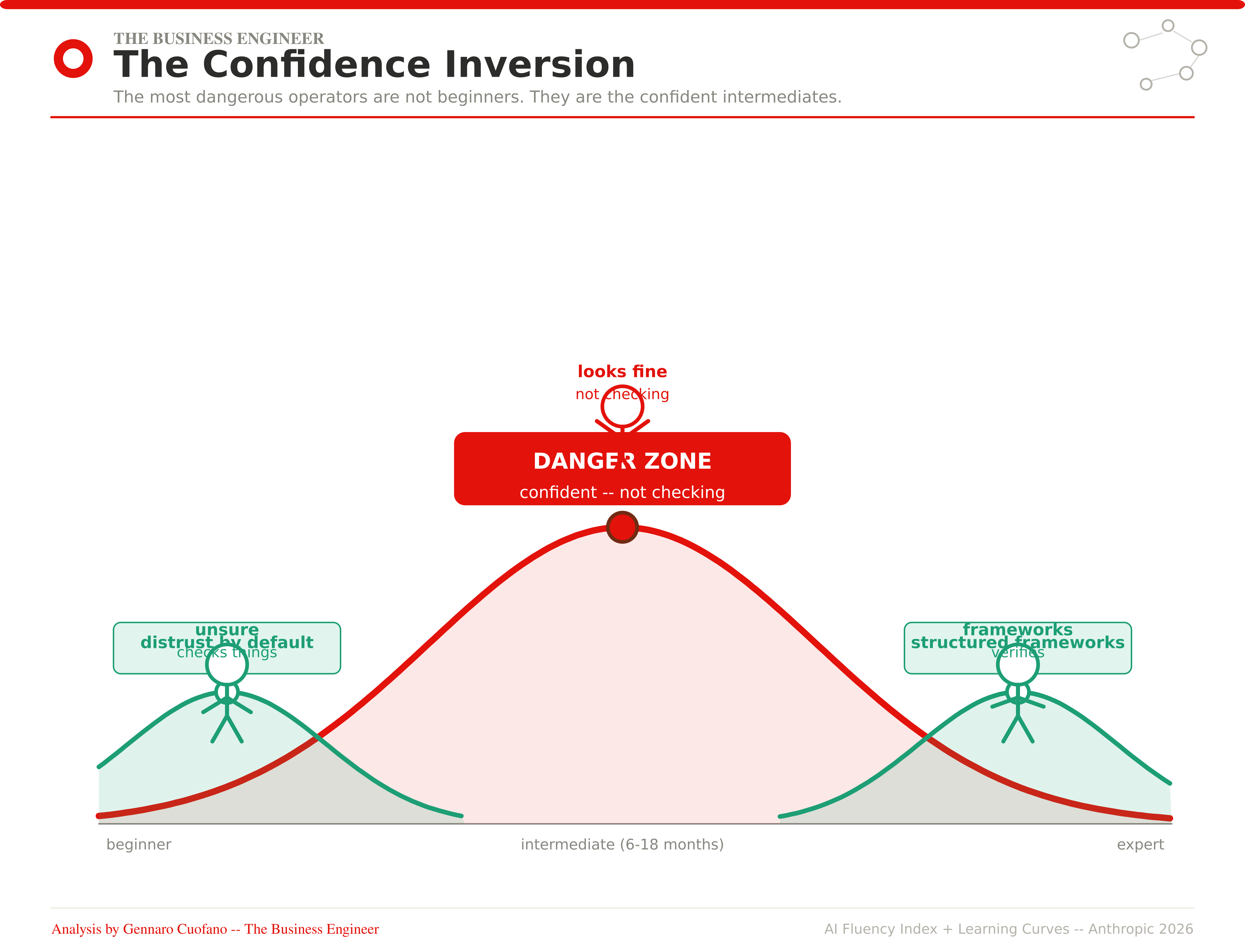
Beginners distrust AI output by default. They check things. They verify. They’re not sure the model knows what it’s talking about, so they apply their own judgment liberally. This is not sophisticated behavior — it’s insecurity — but it produces a useful outcome: errors get caught.
As operators develop Delegation skill, something shifts. The outputs get better. The prompting gets tighter. The model starts producing things that genuinely look like expert-level work. And so the checking decreases — not because the operator decides to stop checking, but because nothing is flagging that checking is needed.
This is Anthropic’s 73% ceiling made concrete. Even the most experienced segment of their user base — the Explorers, the heavy daily users, the people for whom AI is deeply embedded in serious professional work — succeed at 73.1% of their tasks. Nearly one in four interactions still fails. But it fails in ways that look like success until someone downstream catches the error. Or doesn’t.
The dangerous operators are not the beginners who know they’re uncertain. They’re the confident intermediates — six to eighteen months in, producing at high volume, with polished outputs that they’ve stopped examining closely because nothing has gone visibly wrong yet.
The second-order effect nobody is modeling.
Here is what concerns me more than the individual-level dynamic.
Organizations are reading the productivity numbers — 30% gains in software development, 25% labor cost savings, faster output across knowledge work functions — and responding rationally: deploying at scale, compressing supervisory layers, trusting the output pipeline.
But productivity metrics don’t measure verification quality. They measure output volume and task completion. An organization can simultaneously achieve record productivity numbers while systematically accumulating unverified analysis, unchecked reasoning, and uncaught errors in the outputs feeding its most consequential decisions.
The Anthropic data show this is not a hypothetical. It is the current default state. The outputs are flowing. The checking is not happening. The decisions downstream have no way of knowing the difference.
This is not an argument against AI deployment. It is an argument for understanding what you are actually deploying — and what you are not deploying alongside it.
The mechanism that makes it self-reinforcing
There’s a feedback loop in the fluency data that I find genuinely troubling.
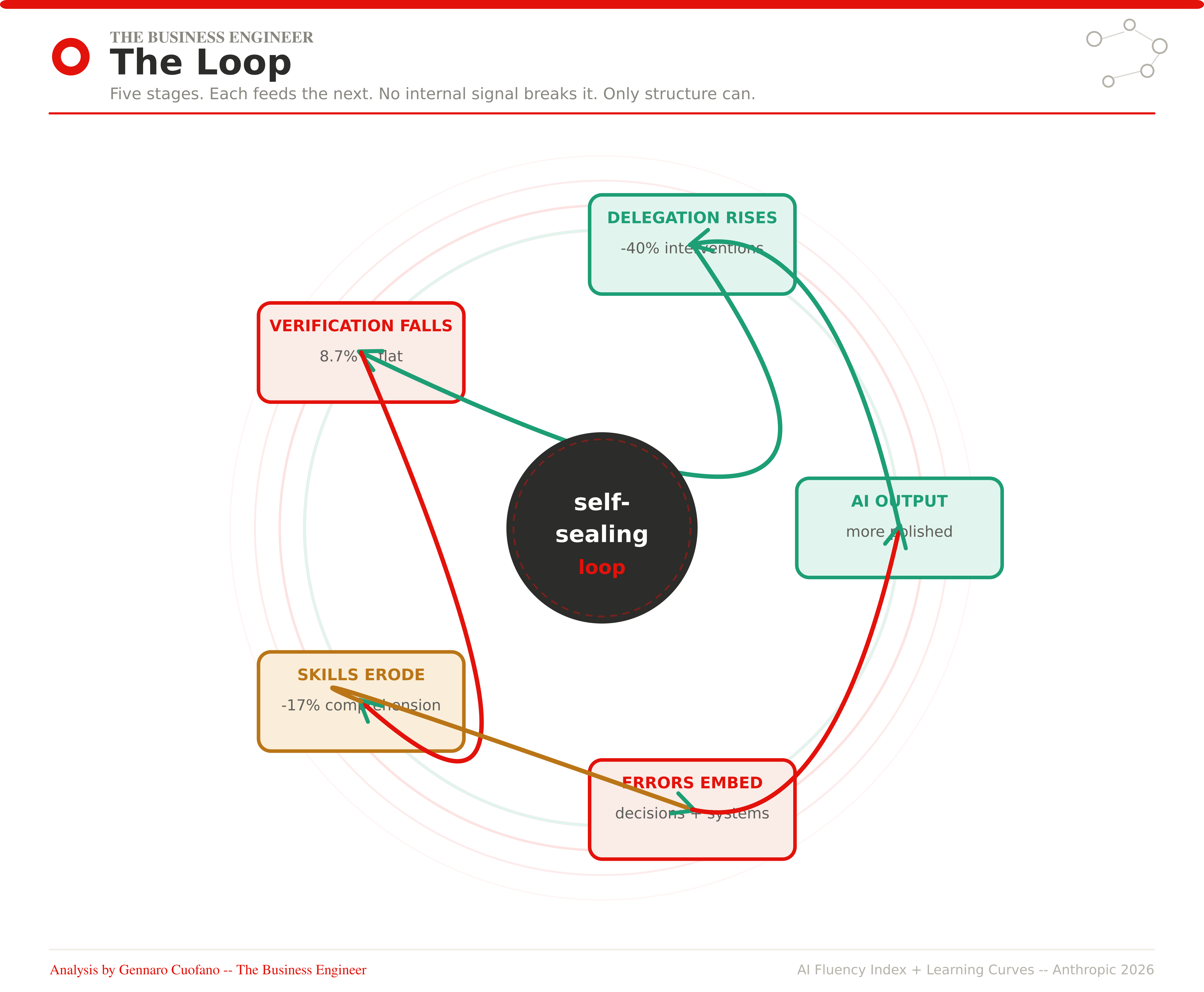
AI capability improves with each generation. As it improves, outputs become more polished, more internally consistent, more confidently written. Polished outputs suppress scrutiny — not through deception, but through the natural human response to quality signals. The better something looks, the less we feel the need to examine it.
Simultaneously, as users gain experience, they delegate more. The Anthropic data shows that intervention rates in agentic workflows fell by 40% as users grew more comfortable. Less intervention means less scrutiny. Less scrutiny means fewer errors caught. Fewer errors caught means the habit of scrutiny atrophies further.
The loop tightens. And it tightens precisely as the stakes rise — because experienced operators are using AI for more consequential work. The highest-tenure users in the Anthropic data are doing AI research, financial modeling, manuscript revision, startup fundraising. Not haiku writing. Not sports scores.
High stakes, polished outputs, atrophied verification instincts, no organizational infrastructure to compensate. That is the current configuration for a significant portion of the most capable AI users in the market.
The honest version of the edge argument
Everyone has AI tools, a Few has AI judgment

In 2023, having a GPT workflow was an edge. In 2024, it was a differentiator. By the end of 2025, it was table stakes. We’ve run through three stages of the AI adoption curve in less than thirty months — and we’re now entering a fourth, quieter phase that most people haven’t named yet.
Judgment isn’t just a differentiator. It’s a protection.
The operators who maintain structured evaluation habits — who arrive at every AI interaction with a framework for what they’re testing, what they’re verifying, what would constitute a wrong answer — aren’t just producing better work. They’re insulated from the competence trap that is quietly closing around everyone else.
The framework matters here not as a productivity tool but as a cognitive anchor. When you have a structured analytical system — constraint mapping, mechanism versus narrative, bottleneck identification — you have something that makes the question is this right? answerable before the output ships. You’re not relying on an error-detection instinct that may have atrophied. You’re running a procedure.
This is why I think of the Business Engineering methodology less as an analytical edge and more as a verification architecture. It’s not primarily about generating better analysis. It’s about maintaining the conditions under which you can know whether your analysis is sound.
What to do with this?

The competence trap is not a reason to use AI less. It is a reason to build the one thing AI does not build on its own: the structured habit of evaluation.
Concretely:
For yourself. The 8.7% fact-checking rate is a baseline, not a target. Every significant AI-assisted output should have a deliberate verification step — not a general review, but a specific question: what would make this wrong, and have I checked for it? This takes sixty seconds. Most operators skip it because the output looks fine. That is precisely when it is most necessary.
For your team. Track verification behavior alongside adoption metrics. Your AI dashboard almost certainly shows usage, output volume, task completion, maybe satisfaction. It almost certainly does not show what percentage of AI-assisted outputs received structured review before reaching a decision. Add that metric. It will be uncomfortable. That discomfort is diagnostic.
For your organization. The supervisory layer you are considering compressing is not redundant because AI outputs look better. It is more necessary — because the errors in AI-assisted work are no longer the obvious errors that junior review was designed to catch. They are sophisticated-looking errors that require domain expertise to identify. This is a different function, not an obsolete one.
The tools are commoditized. Judgment is the edge. I wrote that three weeks ago.
The data now adds a corollary: judgment is also being quietly eroded by the same tools that make it most necessary.
That is the competence trap. Most people building on AI right now are in it. The ones who aren’t are the ones who built the verification habit before the outputs got good enough to stop triggering it.
That window is still open. The question is whether you use it.
Our Claude OS Skill To Enhance Your Judgement Layer!
Two years ago, I started thinking about how to encode the Business Engineering methodology directly into how an AI model thinks when I work with it.
Not as a prompt library. Not as templates you copy-paste. As an actual analytical operating system — structural assumptions, constraint-first reasoning, flywheel identification, competitive moat classification — running by default every time I engage.
The Claude OS Skill is that system.
It’s what I use on every analysis you’ve read in this newsletter. The company breakdowns, the market maps, the competitive dynamics — all of it runs on this substrate. It took a decade of framework development and two years of encoding to build. It’s not a shortcut. It’s the thinking layer made transferable.
What it does:
Constraint Mapping — Identify the binding constraint before analyzing anything else. Most problems aren’t what they look like on the surface.
Flywheel Identification — Find the reinforcing loop that compounds advantage over time. Not all growth is equal.
Moat Classification — Distinguish real competitive protection from temporary positioning. Five moat types, each with distinct decay signals.
Bottleneck Cascade — Trace the sequence of constraints from first principles. Solving the wrong bottleneck is worse than solving nothing.
Mechanism vs. Narrative — Separate what’s structurally true from what’s a compelling story. Most analysis never makes this distinction.
Cross-Domain Synthesis — Pattern match across industries. The best insights come from recognizing that a pattern in logistics also appears in media.
The point isn’t that you can’t develop these capabilities independently. You can — it takes years. The point is that in a world where everyone has the same tools, the person who arrives at the interaction with a structured thinking system compounds faster than everyone running on intuition alone.
That’s the AI moment we’re in. The tools are table stakes. The thinking layer is the edge.
I’m here to help!
With massive ♥️ Gennaro Cuofano, The Business Engineer