The State of the GPU Economy

The GPU economy represents the most concentrated point of value extraction in the AI stack. With NVIDIA controlling 92% of the discrete GPU market share and 70-95% of AI accelerator revenue, understanding this layer reveals the structural constraints that cascade through the entire AI ecosystem.
This analysis examines the GPU layer through three lenses: the physics of constraint (why supply cannot match demand), the economics of concentration (why NVIDIA’s moat appears structural), and the cascade effects (how GPU scarcity shapes every layer above it).
Key finding: The AI infrastructure buildout is fundamentally different from previous technology cycles because it is driven by excess demand, not oversupply. Companies desperately need more AI compute than we can physically build. This creates structural constraints that ripple through every layer of the stack—from energy utilities to model labs to enterprise applications.

I sit down with you to understand what business goals you want to achieve in the coming months, then map out the use cases, and from there embed the BE Thinking OS into the memory layer of ChatGPT or Claude, for you to become what I call a Super Individual Contributor, Manager, Executive, or Solopreneur.

If you need more help in assessing whether this is for you, feel free to reply to this email and ask any questions!

You can also get it by joining our BE Thinking OS Coaching Program.

Read Also:







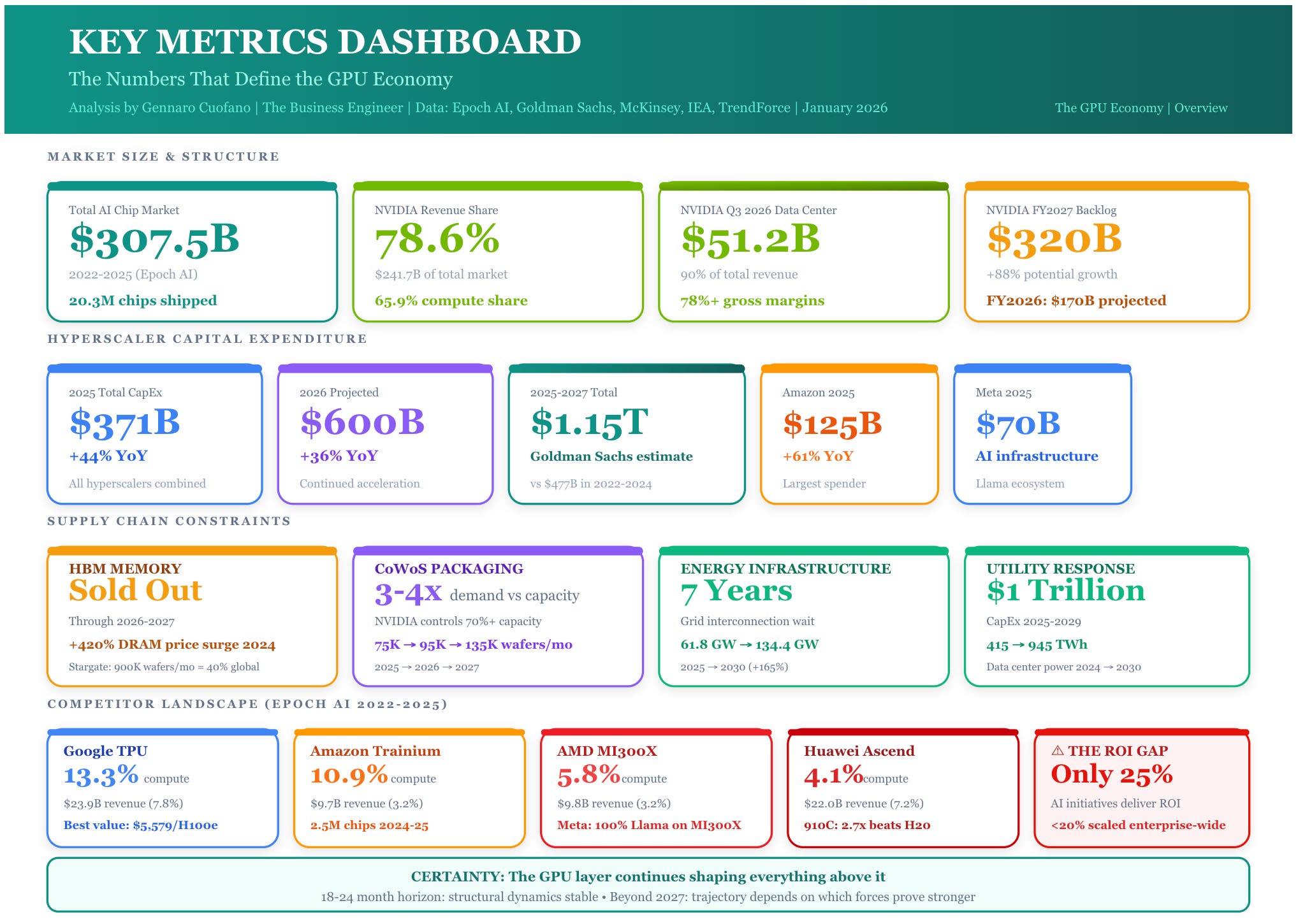
Key Metrics
The Architecture of Constraint
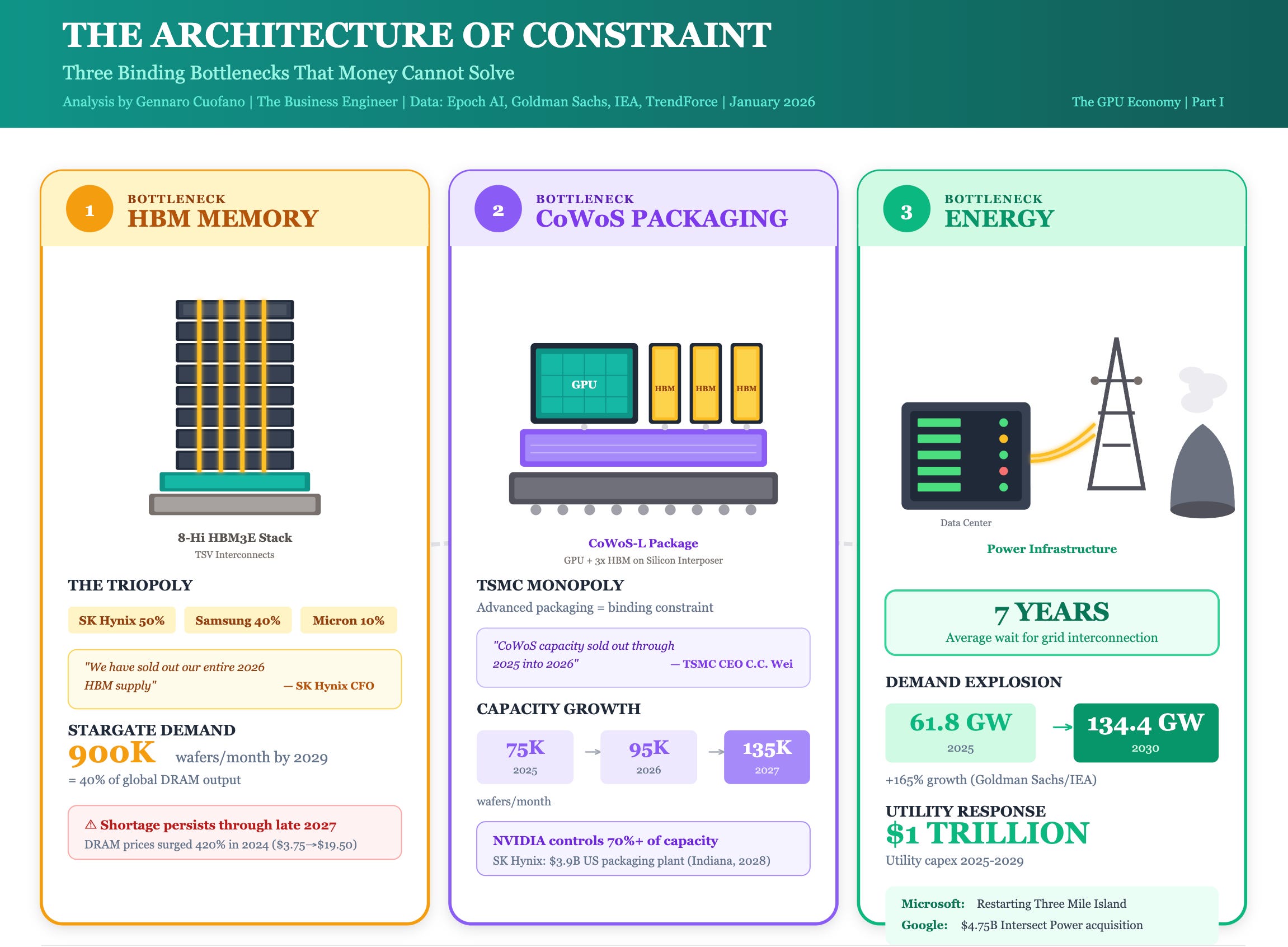
The GPU Supply Chain: Three Binding Bottlenecks
NVIDIA’s ability to ship GPUs depends on three critical chokepoints, none of which it controls. Understanding these constraints explains why money alone cannot solve the AI compute shortage.
Bottleneck 1: High Bandwidth Memory (HBM)
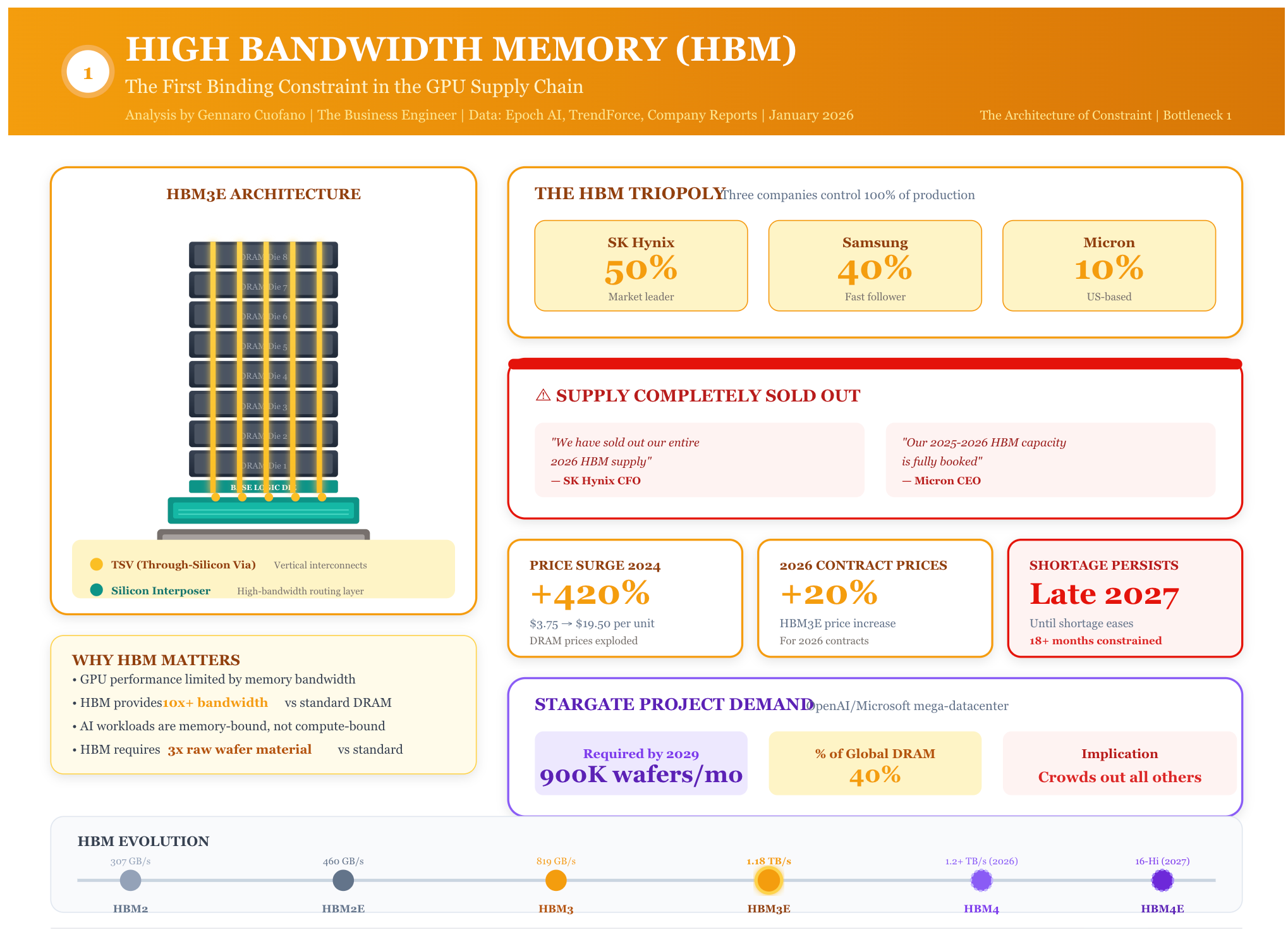
The HBM market is a triopoly: SK Hynix (~50% share), Samsung (~40% share), and Micron (~10% share). All three have their 2025-2026 HBM production sold out. SK Hynix CFO Kim Jae-joon stated explicitly: “We have already sold out our entire 2026 HBM supply.” Micron CEO Sanjay Mehrotra confirmed: “Our HBM capacity for calendar 2025 and 2026 is fully booked.”
The structural problem: HBM requires specialized through-silicon via (TSV) processes that cannot be easily converted from standard DRAM production. Each HBM stack integrates multiple dies and interposers, requiring three times the raw wafer material for identical bit output. New capacity takes years to build, and memory makers are cautious about overbuilding, fearing a future glut if AI demand cools.
OpenAI’s Stargate project alone may require 900,000 DRAM wafers per month by 2029—roughly 40% of current global DRAM output. The shortage may persist through late 2027, according to industry analysts.
The cascade effect is immediate: without HBM, finished GPUs cannot ship. Micron acknowledged it can currently meet only 55-60% of core customer demand. Samsung and SK Hynix have raised HBM3E supply prices by nearly 20% for 2026 contracts, a price increase considered unusual in an industry accustomed to declining costs.
Bottleneck 2: Advanced Packaging (CoWoS)

TSMC’s CoWoS (Chip-on-Wafer-on-Substrate) advanced packaging capacity is the binding constraint on AI chip production. TSMC CEO C.C. Wei was unusually direct: “Our CoWoS capacity is very tight and remains sold out through 2025 and into 2026.”
Current CoWoS capacity: approximately 75,000 wafers per month in 2025, expanding to 95,000 by 2026 and 135,000 by 2027 as new facilities come online. But demand continues to outpace expansion. NVIDIA has secured over 70% of TSMC’s CoWoS-L capacity for 2025, leaving competitors scrambling for the remainder.
The packaging constraint creates a secondary chokepoint: even if memory and logic chips are available, they cannot become finished products without sufficient packaging throughput. This is why SK Hynix is investing $3.9 billion to build its first U.S. packaging plant in Indiana, aiming to deliver turnkey HBM modules by 2028—a fundamental shift from component vendor to full-stack supplier.
Wei emphasized: “Backend capacity for leading-edge nodes is extremely tight.” Orders from NVIDIA, AMD, Google, Amazon, and custom ASIC developers are “overflowing,” leaving TSMC with no spare capacity despite aggressive investment.
Bottleneck 3: Energy Infrastructure

Goldman Sachs projects a 165% increase in data center power demand by 2030. The IEA estimates data centers consumed 415 TWh in 2024, about 1.5% of global electricity, and projects demand could double to 945 TWh by 2030. Utility power demand from data centers will rise by 11.3 GW in 2025 alone to 61.8 GW, nearly tripling to 134.4 GW by 2030.
The constraint isn’t just generation but interconnection. There’s currently a seven-year wait for some requests to connect to the grid. Energy utility capex is expected to surpass $1 trillion cumulatively over the next five years (2025-2029).
Modern AI doesn’t just consume electricity—it devours it at rates that require dedicated power plants. Microsoft’s decision to restart Three Mile Island’s nuclear plant specifically for AI workloads signals the new normal. Google’s $4.75 billion acquisition of Intersect Power underscores how critical energy infrastructure has become to AI strategy.
According to Deloitte’s survey of power company and data center executives, 79% said AI will increase power demand through 2035 due to widespread adoption. Power availability and infrastructure delivery timelines have become the most decisive factors shaping data center site selection.
The Economics of Concentration

NVIDIA’s Three-Layer Moat
NVIDIA’s dominance is not merely a matter of market timing or first-mover advantage. It represents a structural moat built across three reinforcing layers:
Layer 1: The CUDA Ecosystem

CUDA is not just software; it’s a complete ecosystem that took 17 years to build since 2007. Over 4 million developers know CUDA. Thousands of applications depend on it. PyTorch, TensorFlow, and every major deep learning framework are optimized specifically for CUDA. The switching cost is not measured in months but in years of code rewriting and team retraining.
This software moat allows NVIDIA to price hardware at substantial premiums. Competitors like AMD can match silicon performance—MI300X comes close to H100—but they cannot replicate the ecosystem. AMD’s ROCm, Intel’s oneAPI, and OpenCL have all failed to gain significant adoption due to a causality dilemma: developers won’t use them without library support, and library developers won’t support them without users.
AlexNet, the neural network that kickstarted the modern AI revolution, was trained using two NVIDIA GeForce GTX 580 GPUs in 2012. From that moment, NVIDIA became the lingua franca of AI compute. Every subsequent innovation built on CUDA, deepening the moat with each generation.
Layer 2: Supply Chain Lock-in
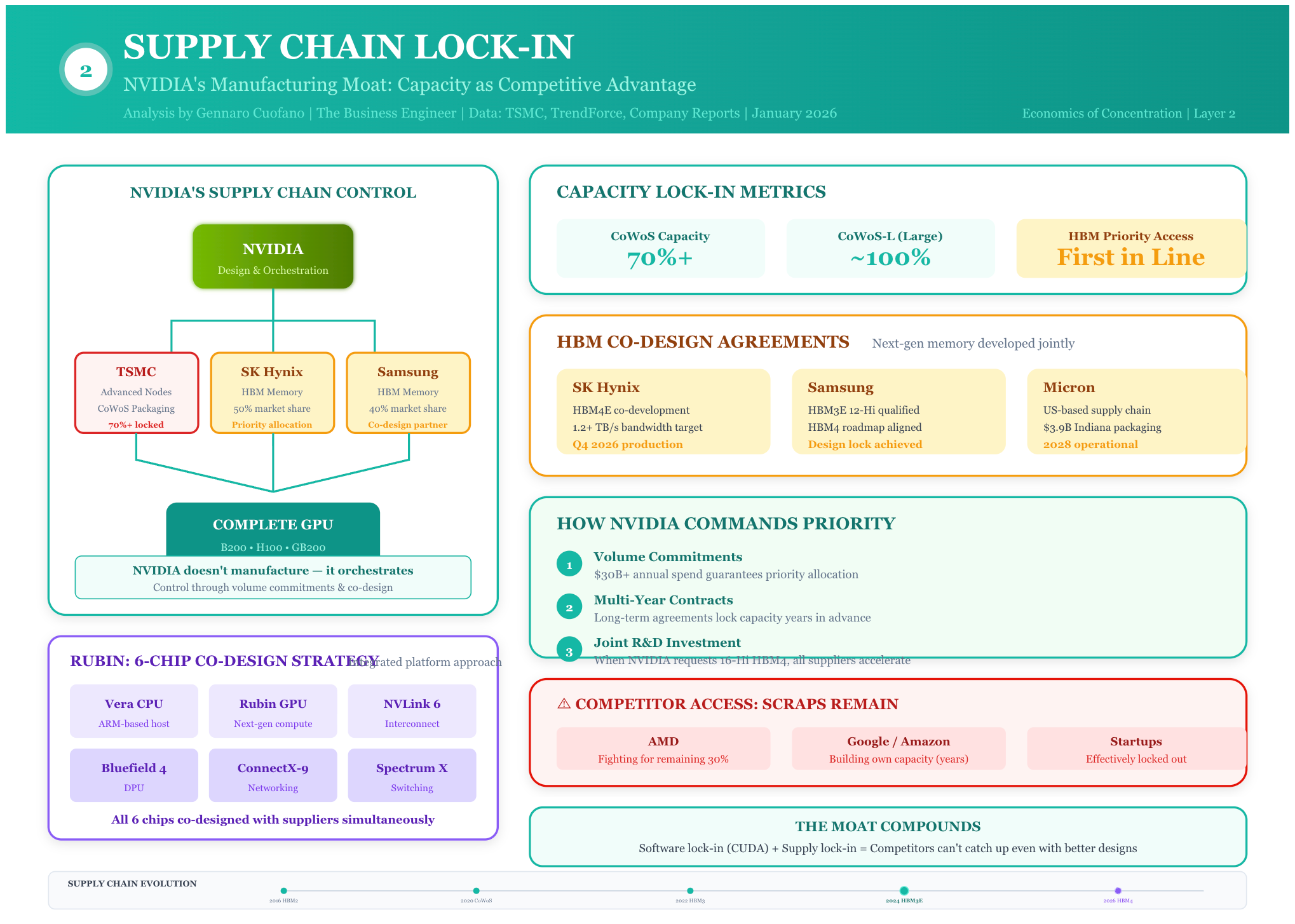
NVIDIA has secured preferential access to every constrained component. It has 70%+ of TSMC’s CoWoS capacity. It has priority allocation from all three HBM suppliers. It has co-design agreements with memory makers for next-generation products. When NVIDIA requests 16-Hi HBM4 by Q4 2026, Samsung, SK Hynix, and Micron all accelerate development simultaneously.
This supply chain position compounds over time. Each generation of chips requires tighter integration with memory and packaging partners. NVIDIA’s Rubin platform, expected in late 2026, will use HBM4E stacks with bandwidth over 1.2TB/s per module—achievable only through deep co-design with suppliers.
The company redesigned six chips together—Vera CPU, Rubin GPU, NVLink 6, Bluefield 4, ConnectX-9, and Spectrum X—to optimize for AI workloads as a system rather than as individual components. This co-design approach delivers multiplicative performance gains that exceed what Moore’s Law alone could provide.
Layer 3: Innovation Velocity
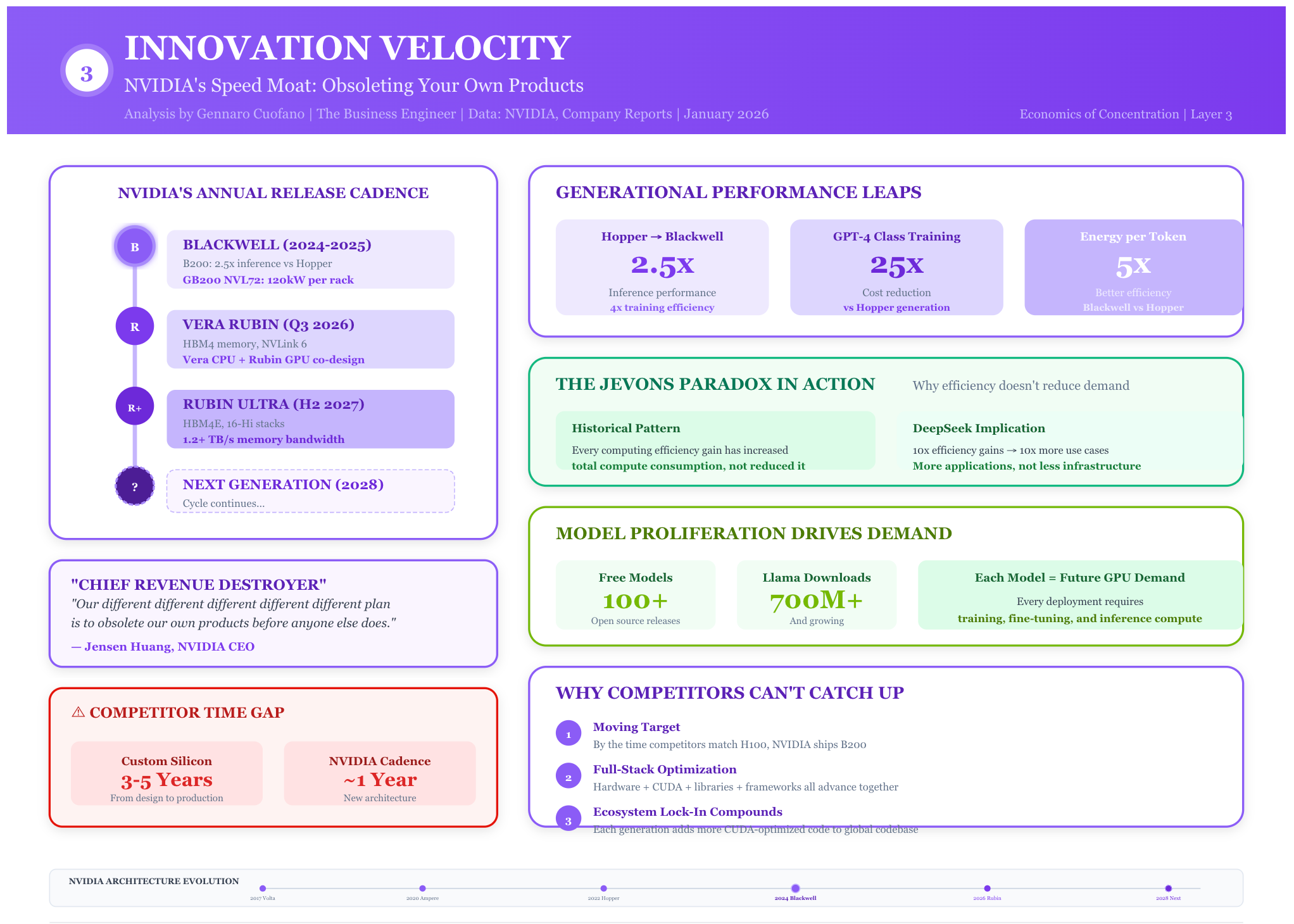
NVIDIA has shifted to an annual architecture release cadence. Jensen Huang calls himself “the chief revenue destroyer,” deliberately accelerating obsolescence. Blackwell (B100/B200) ships in 2025 with ~2.5x inference performance over Hopper. Vera Rubin follows in Q3 2026 with HBM4 support. Rubin Ultra arrives in H2 2027.
Competitors are always 1-2 generations behind. Custom silicon takes 3-5 years to develop. By the time Google’s TPU v7 or AMD’s MI450 ships, NVIDIA has already moved the frontier. This perpetual motion creates a moving target that no competitor can hit.
The razor-razorblade dynamic defines infrastructure economics. NVIDIA released over 100 models for free—Nemotron, Cosmos, Alpamayo, GROOT, and others—because every model download creates future GPU demand. The marginal cost of distributing a model approaches zero. The marginal revenue from each developer trained on NVIDIA’s stack approaches lifetime customer value.
The Margin Story: 78% Gross Margins
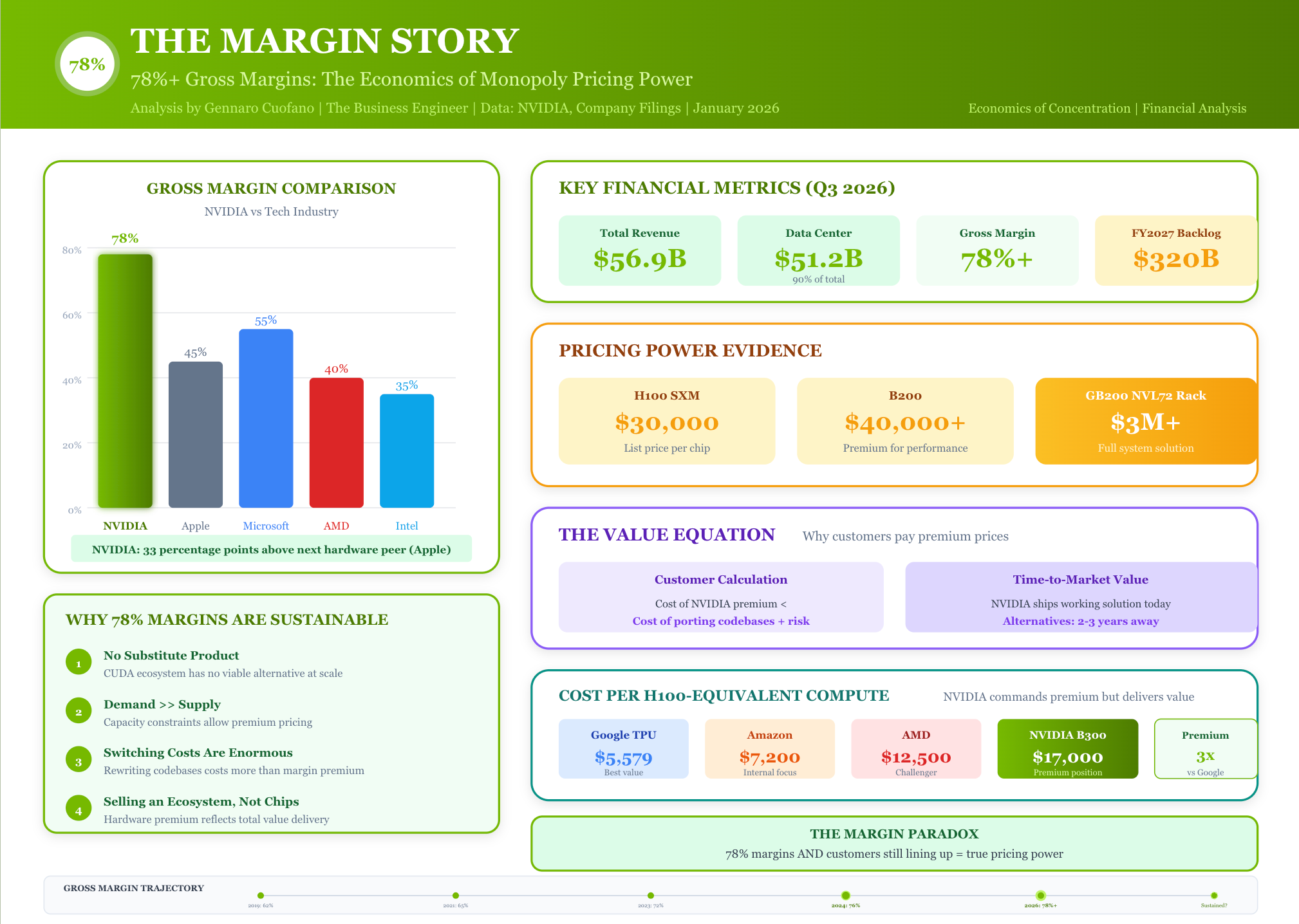
NVIDIA’s gross margins of 78%+ are almost unprecedented for a hardware company. Apple, famous for pricing power, manages only 45%. These margins reflect both technological leadership and structural scarcity. When demand exceeds supply by a factor of 3-4x (as TSMC CEO Wei stated), pricing power is absolute.
Data center revenue reached $51.2 billion in Q3 2026 alone, representing 90% of total company revenue. The company is on track for $170 billion in data center revenue for fiscal 2026, with a reported $320 billion backlog for fiscal 2027. If NVIDIA manages to convert all of that backlog into revenue, its data center revenue could jump by an estimated 88% next year.
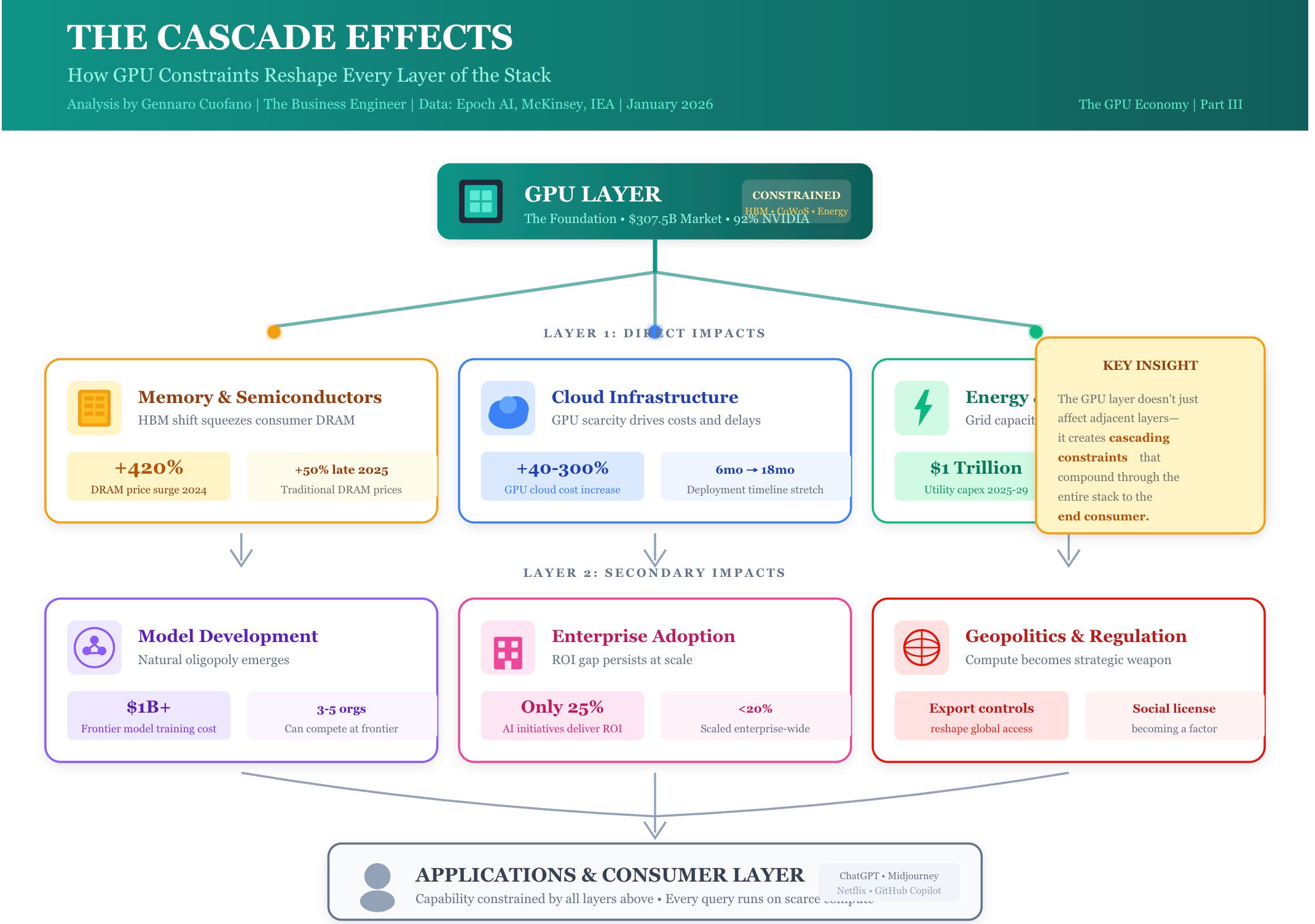
The Cascade Effects